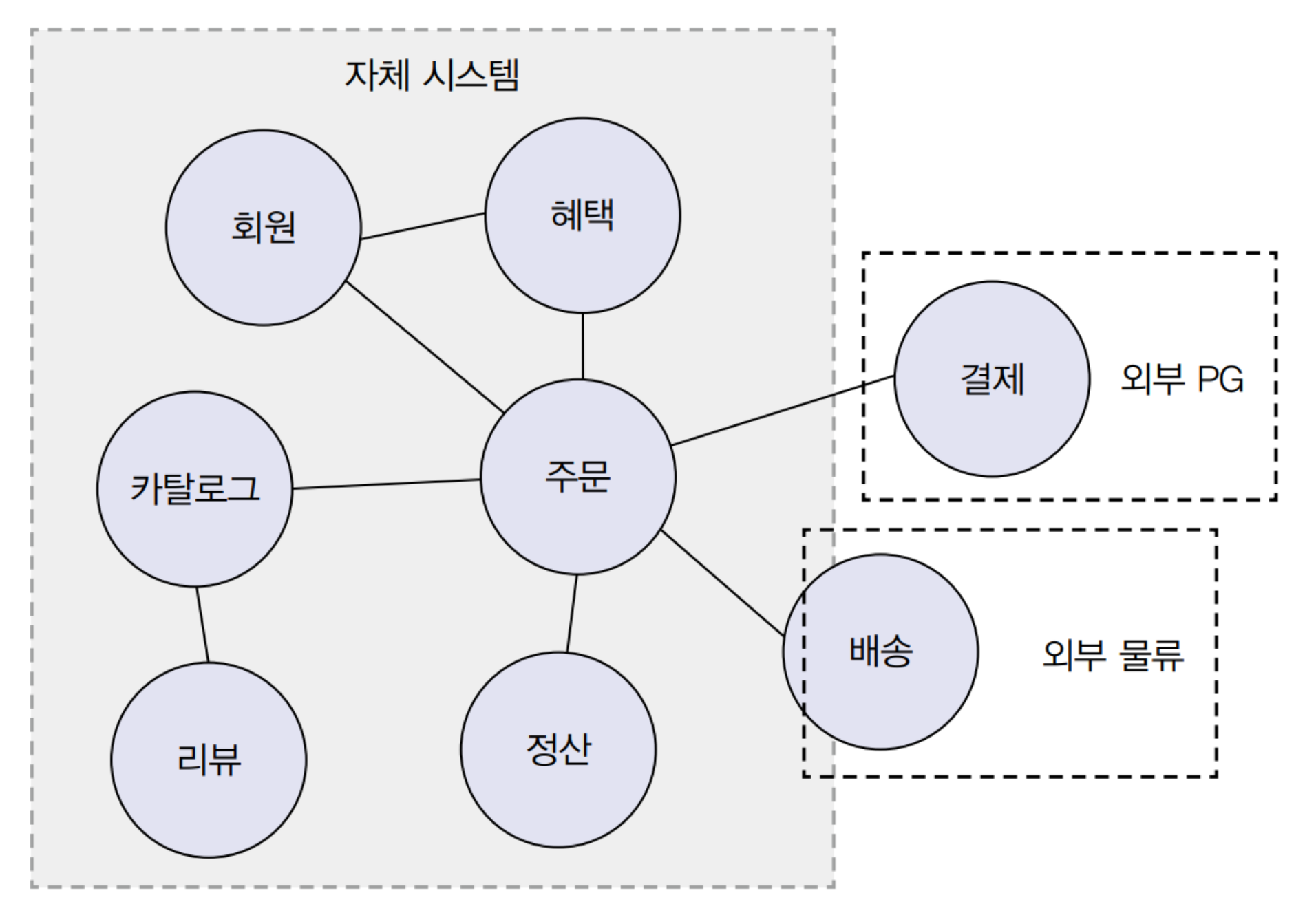
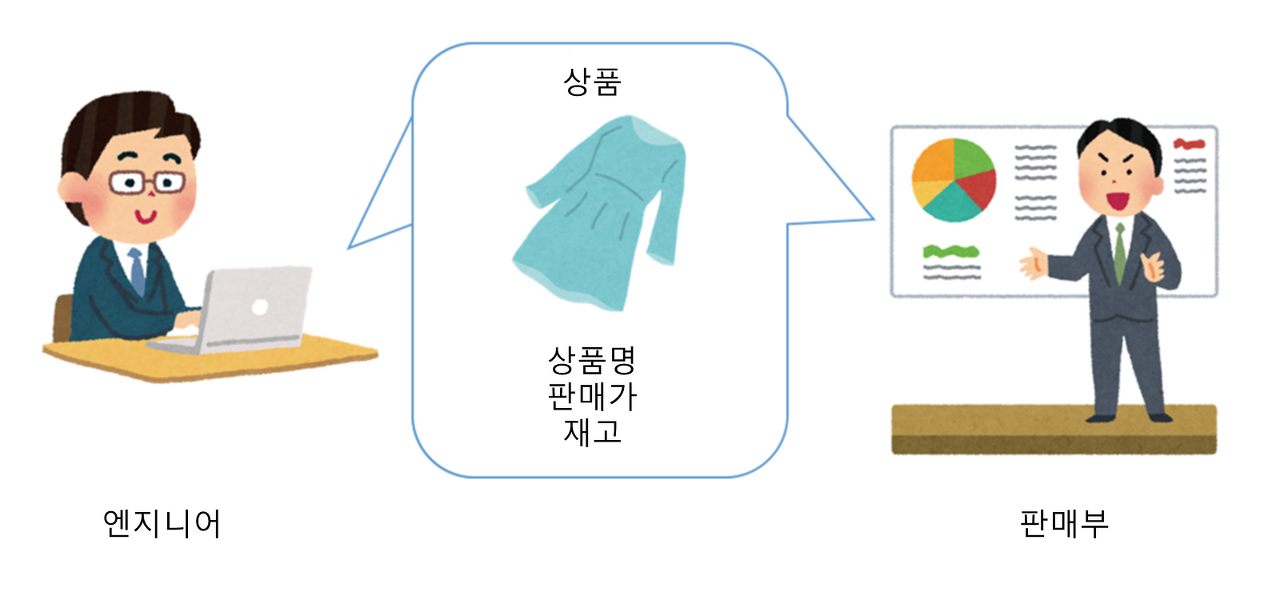
온라인 서점을 구현한다고 해보자. 그럼 우리는 어떤 책이 나왔는지 검색하고, 목차와 서평을 보기도 한다. 그리고 주문하고 결제하고 배송하며, 리뷰를 하기도 한다. 이렇게 우리가 소프트웨어로 해결하고자 하는 모든 영역을 도메인이라고 한다.
앞서 말한 다양한 기능은 하위 도메인으로 볼 수 있다.
하지만 이 중에 배송과 결제 같은 기능은 개발자가 직접 해결하지 않기도 한다.
도메인 모델
도메인 모델 : 특정 도메인을 개념적으로 표현한 것
도메인 모델을 사용해서 여러 관계자들이 동일한 모습으로 도메인을 이해하고 도메인 지식을 공유하는 데 도움이 된다.
도메인 모델링은 다양한 방법을 활용할 수 있다.
주문 도메인을 모델링 해보자.
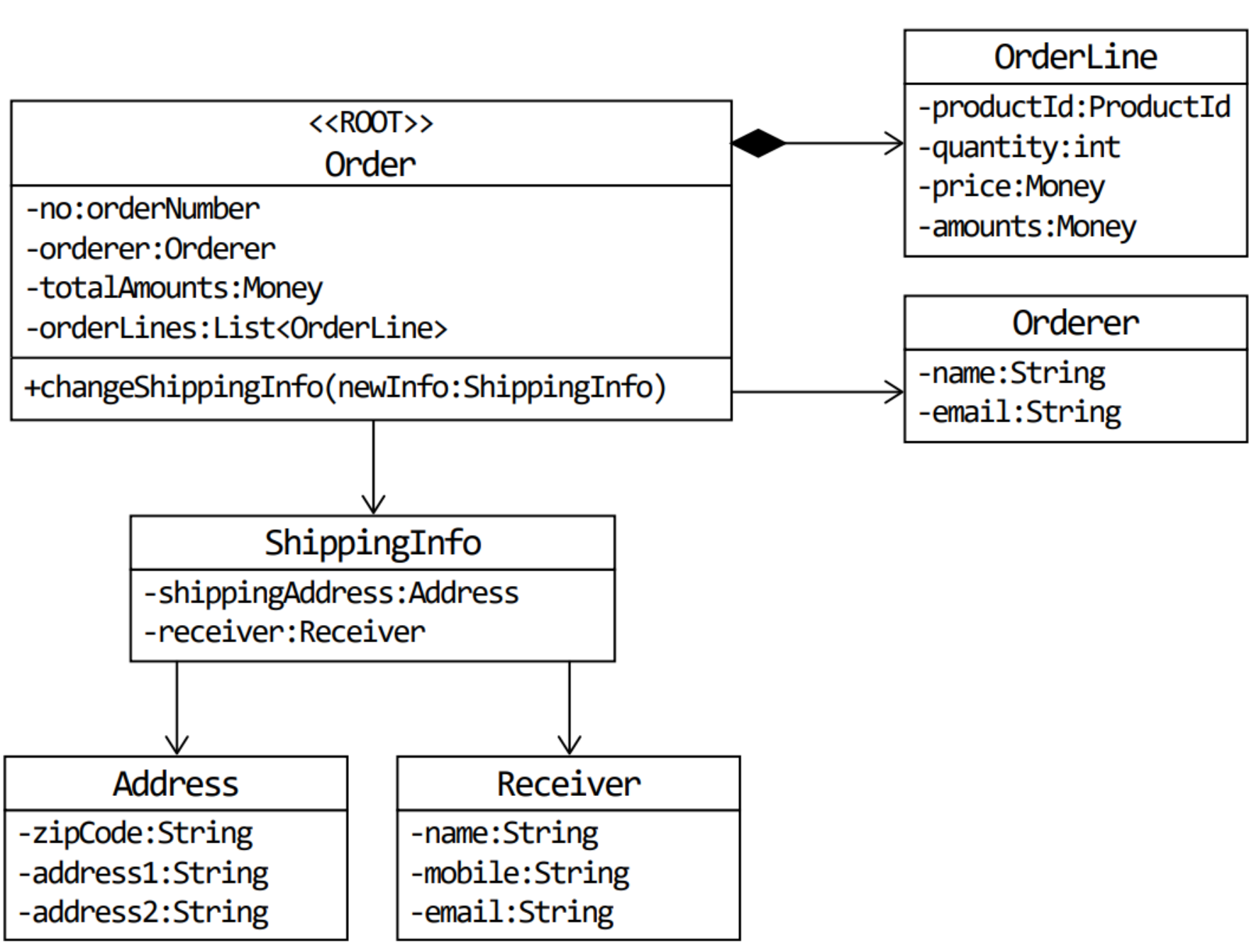
이제 이 그림을 통해 도메인을 이해할 수 있다. 이 모델을 통해 주문은 주문 번호, 지불 금액 등을 가지고 있고, 배송 정보를 변경하거나 주문을 취소할 수 있다는 사실을 알 수 있다.
위의 그림은 객체를 이용한 도메인 모델이다. 객체 모델링은 기능과 데이터를 함께 보여줘서 편리하지만, 다른 방법을 활용할 수도 있다.
이 그림은 상태 다이어그램으로 표현한 도메인 모델이다. 이 다이어그램을 통해 상품 준비 중 상태에서 주문을 취소하면 결제 취소가 함께 이루어진다는 것을 알 수 있다.
상황에 따라서는 그래프를 이용할 수도 있고, 수학 공식을 이용할 수도 있다. 중요한 것은 도메인을 이해하는데 도움만 되면 된다는 것이다.
도메인 모델 패턴
영역
설명
사용자 인터페이스 또는 표현
요청을 처리하고 사용자에게 정보를 보여준다. 여기서 사용자는 소프트웨어를 사용하는 사람 뿐만 아니라 외부 시스템일 수도 있다.
응용
사용자가 요청한 기능을 실행한다. 업무 로직을 직접 구현하지 않으며 도메인 계층을 조합해서 기능을 실행한다.
도메인
제공할 도메인 규칙을 구현한다.
인프라스트럭처
메시징 시스템과 같은 외부 시스템과의 연동을 처리한다.
전체적인 아키텍처와 각 영역은 뒤에서 자세히 설명한다.
도메인 모델 도출
개발의 시작은 도메인에 대한 이해이다. 기획서, 유스케이스, 사용자 스토리와 같은 요구사항을 통해 도메인 모델 초안을 만들어야 비로소 코드를 작성할 수 있다.
예컨데, 주문 요구사항을 모델링 하면 다음과 같다.
엔티티와 벨류
앞선 요구사항 분석 과정에서 만든 모델은 다음과 같다.
도출한 엔티티 모델의 각 요소는 엔티티와 벨류로 구분할 수 있다.
엔티티
식별자를 가진다.
내용이 바뀌어도 식별자가 변하지 않는다.
벨류타입
개념적으로 완전한 하나를 표현할 때 사용한다.
벨류타입을 위한 기능을 추가할 수 있다.
불변으로 구현해야 한다.(Setter 금지!)
개념적으로 완전히 하나를 표현
벨류 타입을 위한 기능
아키텍처 개요
DDD 아키텍처
응용 영역이나 도메인 영역은 인프라 기능을 사용하므로 인프라 계층에 종속된다. 이는 2가지 문제를 가져온다.
인프라가 구현되기 전까지 테스트가 어렵다.
구현 방식을 변경하기 어렵다.
코드만 보면 DI로 해결할 수 있을 것 같지만, 간접적인 의존이 존재한다.
DIP
DIP = 의존 관계 역전 원칙 = 저수준 모듈이 고수준 모듈에 의존하도록 바꾼다.
주의 사항
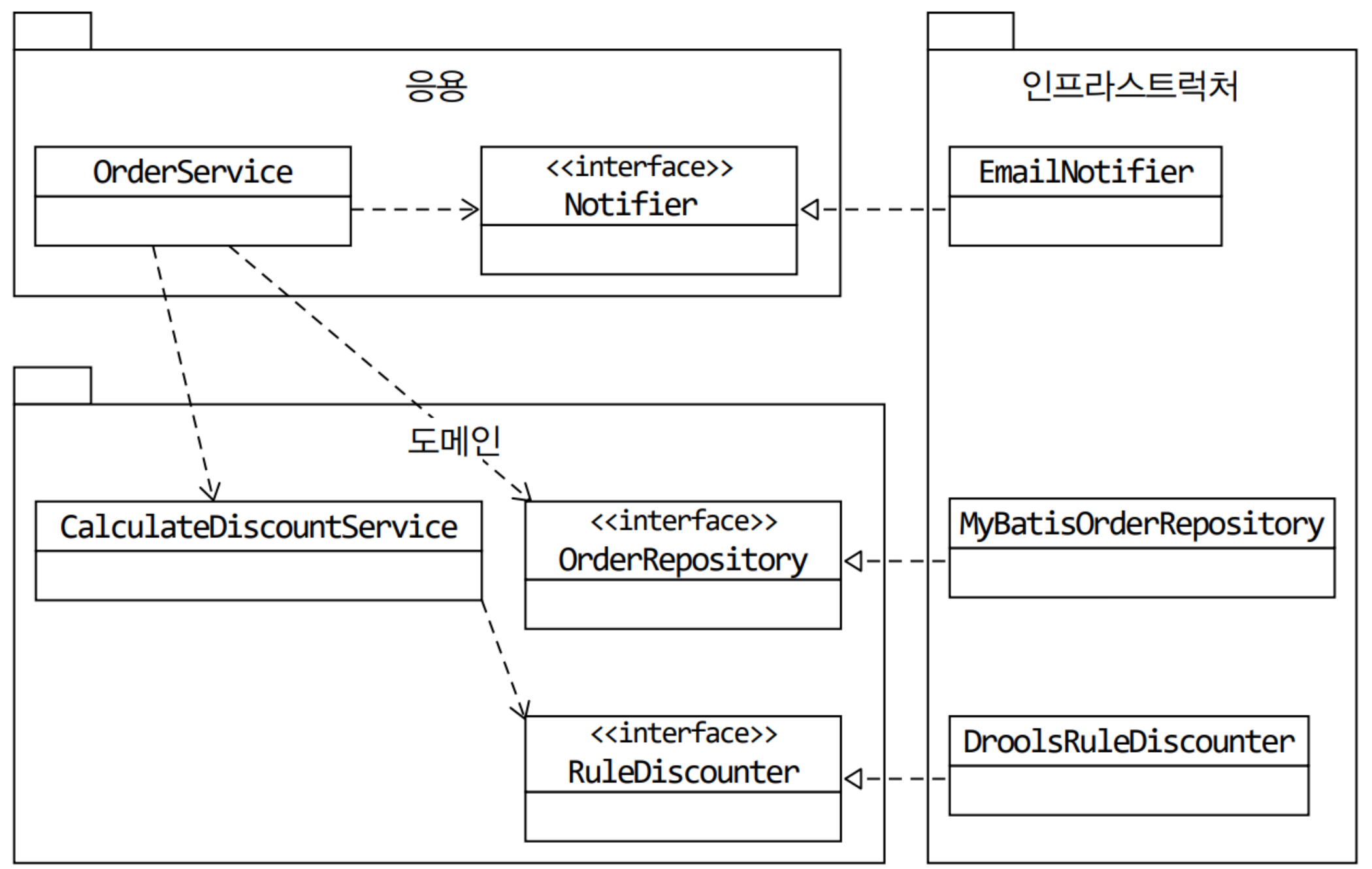
단순히 DroolsRuleDiscounter에서 인터페이스를 분리한다고 생각하면 안된다. 인터페이스는 고수준 모듈 입장에서 도출해야 한다. 따라서 인터페이스는 저수준 모듈이 아닌 고수준 모듈에 위치한다.
도메인 영역의 주요 구성요소
애그리거트
도메인이 커질수록 도메인 모델은 복잡해지고 엔티티와 벨류 개수가 많아진다. 이때 도움이 되는 개념이 애그리거트이다. 애그리거트는 관련 객체를 하나로 묶은 군집이다.
예컨데 온라인 서점 서비스에서 주문은 하나의 애그리거트가 된다. 이때 애그리 거트는 군집에 속한 객체를 관리하는 루트 엔티티를 갖는다. 루트 엔티티는 애그리거트에 애그리거트가 구현해야 할 기능을 제공한다.(애그리거트 단위로 구현을 캡슐화한다.)
모듈 구조
애그리거트
도메인 모델이 복잡해지면 관계를 파악하기 어렵고 확장이 어려워진다. 이를 해결하기 위해 거대한 도메인 모델을 작은 애그리거트 단위로 나눈다.
애그리거트에 속한 객체는 유사하거나 동일한 라이프 사이클을 가진다.
애그리거트는 경계를 갖는다.
한 애그리거트에 속한 객체는 다른 애그리거트에 속하지 않는다
애그리거트는 자기 자신만 관리할 뿐, 다른 애그리거트를 관리하지 않는다.
경계는 도메인 규칙과 요구사항으로 결정된다.(생명 주기를 살펴보자.)
흔히 ‘A가 B를 갖는다’로 설계할 수 있는 요구사항이 있다면 A와 B를 한 애그리거트로 묶어서 생각하기 쉽다. 주문의 경우 Order가 ShippingInfo와 Orderer를 가지므로 이는 어느 정도 타당해 보인다. 하지만 ‘A가 B를 갖는다’로 해석할 수 있는 요구사항이 있다고 하더라도 이것이 반드시 A와 B가 한 애그리거트에 속한다는 것을 의미하는 것은 아니다.
좋은 예가 상품과 리뷰다. 상품 상세 페이지에 들어가면 상품 상세 정보와 함께 리뷰 내용을 보여줘야 한다는 요구사항이 있을 때 Product 엔티티와 Review 엔티티가 한 애그리거트에 속한다고 생각할 수 있다. 하지만 Product와 Review는 함께 생성되지 않고, 함께 변경되지도 않는다. 게다가 Product를 변경하는 주체가 상품 담당자라면 Review를 생성하고 변경하는 주체는 고객이다.
애그리거트 루트
애그리거트는 개념적으로 하나이기 때문에 모든 객체가 일관된 상태를 유지해야 한다. 예컨데, 주문 애그리거트에서 상품 가격이 변경되면 총 금액도 변경되어야 하는 것이다. 이러한 애그리거트에 속한 모든 객체의 일관성을 유지하는 책임을 지는 것이 애그리거트 루트이다.
이 목표를 달성하기 위한 3가지 원칙이 있다.
애그리거트의 모든 기능은 애그리거트 루트를 통해 실행한다.
단순히 필드를 변경하는 set 메서드는 public으로 만들지 않는다.
밸류 타입은 불변으로 구현한다.
애그리거트의 트렌젝션
트렌젝션은 작을수록 좋다. 한 트렌젝션이 여러 테이블을 변경하면 성능이 떨어지기 때문이다. 동일하게 한 트렌젝션에서는 한 개의 애그리거트만 수정해야 한다.
만약 부득이하게 한 트렌젝션에서 두 애그리거트를 수정해야 한다면 다음과 같은 방법을 고려할 수 있다.
Application 계층에서 애그리거트를 사용하는 트렌젝션을 구현
도메인 이벤프를 사용해서 동기 또는 비동기로 다른 애그리거트의 상태를 변경
다른 애그리거트를 사용하는 트렌젝션의 예시
리포지터리와 애그리거트
애그리거트는 개념상 완전한 한 개의 도메인 모델을 표현하므로 영속성을 처리하는 리포지터리는 애그리거트 단위로 하나만 존재한다. 따라서 리포지터리는 완전한 애그리거트를 제공해야 하고, 저장시 애그리거트 전체를 영속화 해야 한다.
ID를 이용한 애그리거트 참조
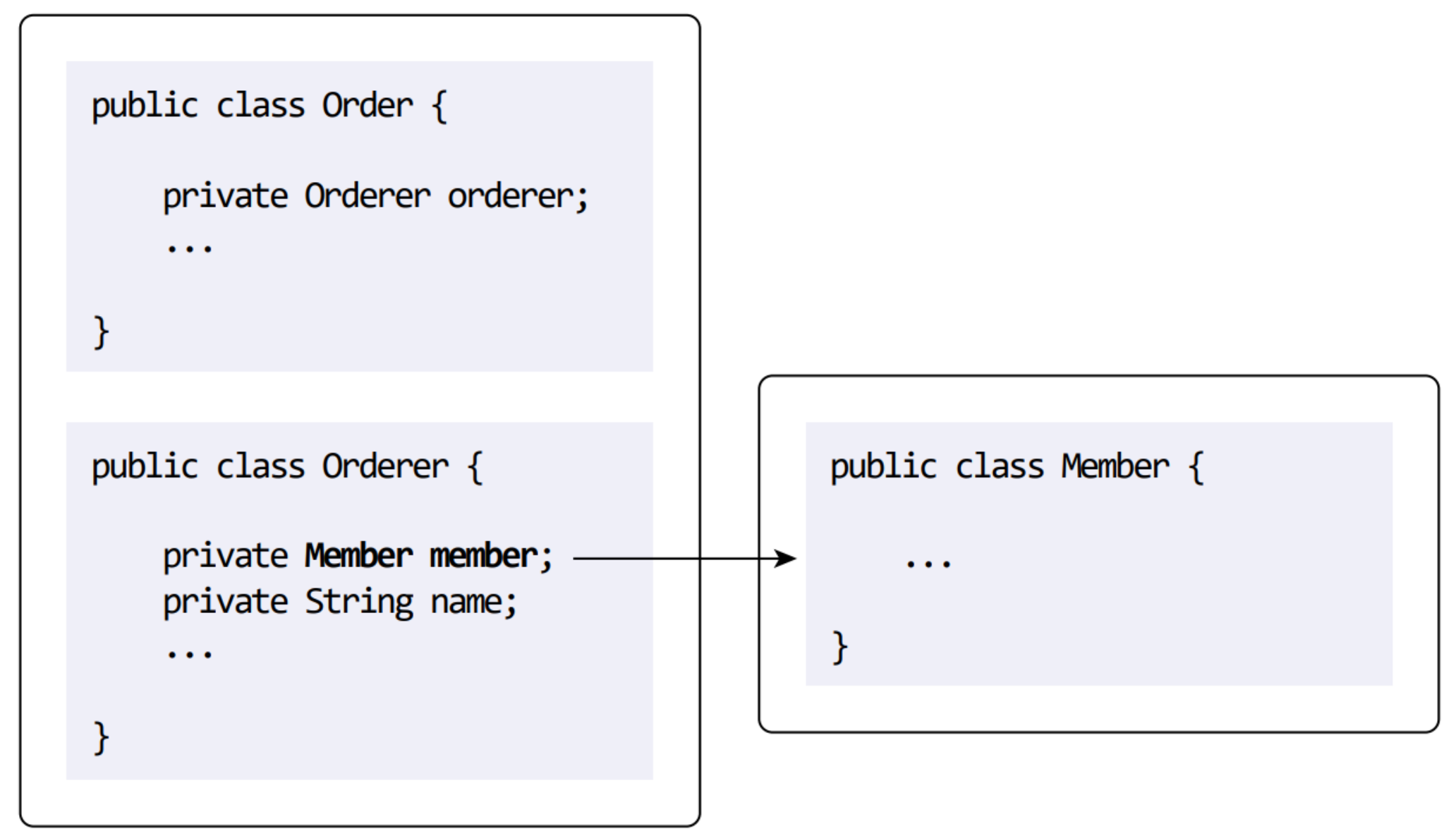
한 애그리거트가 다른 애그리거트를 참조하기도 한다. 가장 쉬운 방법은 회원 애그리거트 루트인 Member를 참조할 수 있다.
하지만 이 방식은 다음과 같은 문제를 가지고 있다.
편한 탐색 오용 - 다른 애그리거트 상태를 쉽게 변경할 수 있음.
성능에 대한 고민 - 지연/즉시 로딩 방법 고민
확장 어려움 - 다른 애그리거트가 같은 DBMS를 사용하지 않게 된다면?
따라서 다른 애그리거트의 루트를 참조하는 것이 아니라, ID만 가지고 있는 방식으로 애그리거트 참조를 구현한다.
성능 문제가 발생하지 않을까요?
다른 애그리거트를 ID로 참조하면 N+1 문제가 발생한다. 그렇다고 JOIN 사용하면 ID참조 방식에서 객체 참조 방식으로 되돌리는 꼴이다. 이를 해결하기 위해 조회 전용 쿼리를 사용하는 것이 좋다.
이후에 CQRS 패턴에서 더 자세히 알아본다.
응용 서비스와 표현 영역
표현 영역은 사용자의 요청을 해석한다.
응용 영역은 사용자가 원하는 기능을 제공한다.
응용 서비스의 역할
응용 서비스는 사용자가 요청한 기능을 실행한다. 이를 위해 리포지터리에서 도메인 객체를 가져와 사용한다.
응용 서비스의 역할
도메인 객체 간의 흐름을 제어한다. (facade pattern을 생각하면 편하다)
트랜잭션 처리를 담당한다.
기능의 인가 확인
응용 서비스의 주의사항
도메인 로직 넣지 않기
응용 서비스의 고민거리
응용 서비스의 크기
회원 도메인을 생각하면, 회원 가입 탈퇴 암호 변경 비밀번호 초기화와 같은 기능을 한 응용 서비스에 다 넣을지 기능 별로 응용 서비스를 만들지 고민하게 된다.
한 클래스에 넣으면 코드 중복을 줄이게 된다. 하지만 응집도가 낮아진다.
응용 서비스에 인터페이스가 필요한가?
인터페이스는 테스트의 용이성과 확장의 용이성을 얻을 수 있다. 하지만 응용 서비스는 변경이 잦지 않고, Mockito와 같은 프레임워크로 테스트 용이성을 얻을 수 있다. 따라서 인터페이스는 전체 구조를 복잡하게 하는 나쁜 선택일 가능성이 높다.
표현 영역
표현 영역의 책임은 크게 다음과 같다.
사용자가 시스템을 사용할 수 있는 흐름(화면)을 제공하고 제어한다.
사용자의 요청을 알맞은 응용 서비스에 전달하고 결과를 사용자에게 제공한다.
사용자의 세션을 관리한다.
값 검증
값 검증은 표현 영역과 응용 서비스 두 곳에서 수행할 수 있다.
원칙적으로 모든 값에 대한 검증은 응용 서비스에서 처리한다. 하지만 Spring 프레임워크의 기능을 편리하게 사용하기 위해서 표현 영역에서도 값 검증을 수행하는 것이다(이는 Spring의 ModelAndView에 BindingResult를 활용하거나, Validator 기능을 활용하기 위함이다).
프레임워크를 활용하면 다음과 같이 역할을 나누어 검증을 수행할 수 있다.
표현 영역: 필수 값, 값의 형식, 범위 등 검증
응용 서비스: 데이터의 존재 유무와 같은 논리적 오류 검증
저자(최범균)은 최근에는 응용 서비스에서 필수 값 검증과 논리적인 검증을 모두 한다고 한다. 이는 응용 서비스의 완성도가 높아지는 이점이 있다고 한다.
권한 검사
권한 검사는 보통 3가지 영역에서 수행할 수 있다.
표현 영역
인증된 사용자인지 검증한다.
필터를 활용한다.
응용 서비스
URL만으로 접근 제어를 할 수 없는 경우 메서드 단위로 검사를 수행한다.
AOP를 활용한다.
도메인
게시글 삭제는 본인 또는 관리자만 할 수 있는 경우에는 도메인에서 권한 검사를 구현해야한다.
도메인 서비스
여러 애그리거트가 필요한 기능
특정 기능은 여러 애그리거트가 필요하다. 대표적인 예가 결제 금액 계산 로직이다.
상품 애그리거트: 구매하는 상품의 가격이 필요하다. 또한 배송비가 추가되기도 한다.
주문 애그리거트: 상품별로 구매 개수가 필요하다
할인 쿠폰 애그리거트: 쿠폰별로 할인을 받는다. 이때 카테고리별로 제약이 있다면 더 복잡해진다.
회원 애그리거트: 회원 등급에 따라 추가 할인이 가능하다.
이 내용을 한 애그리거트에 포함 시키면 책임을 넘는 기능을 구현하고, 외부 의존이 높아지며, 코드가 복잡해진다. 또한 애그리거트의 범위를 넘는 도메인 개념이 애그리거트에 숨어든다.
도메인 서비스
도메인 서비스는 상태를 가지지 않는다
구현에 필요한 상태는 다른 방법으로 전달 받는다(Param)
도메인 서비스를 사용하는 주체는 애그리거트가 될 수도 있고 응용 서비스가 될 수도 있다.
애그리거트 객체에 도메인 서비스를 전달하는 것은 응용 서비스 책임이다.
외부 시스템 연동과 도메인 서비스
외부 시스템이나 타 도메인과의 연동 기능도 도메인 서비스가 될 수 있다. 이는 도메인 관점에서 작성된 Interface와 실제 구현 부인 Infra가 포함된다.
설문 조사 도메인에서 설문 조사 생성 권한을 확인해야 할 수 있다. 이때 확인은 Member도메인과 연동이 필요하다.
이렇게 만든 도메인 서비스는 도메인 계층에 위치한다.
도메인 모델과 바운디드 컨텍스트
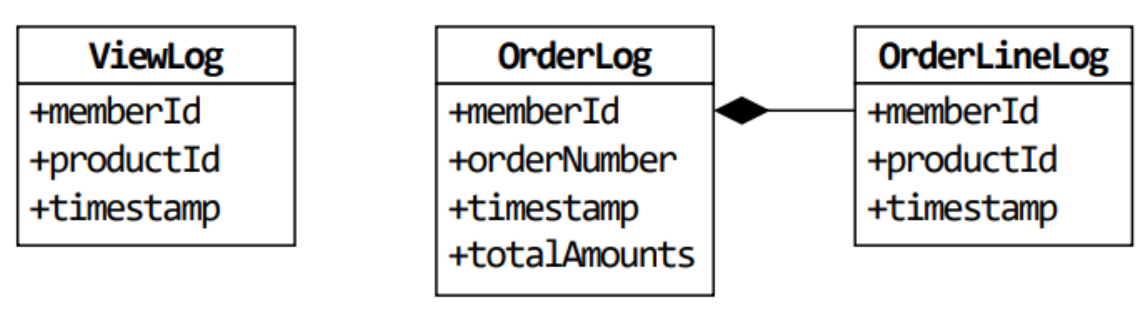
DDD는 모든 사람(소프트웨어 개발자, 도메인 전문가)이 동일한 의미로 말을 사용하는 것을 목적으로 한다. 하지만 도메인 모델에서는 개념적으로는 같은 것이 맥락에 따라 달라지는 경우가 있다. 아래의 그림을 보자.
개념적으로 같은 것이 맥락에 따라 달라지는 경우
이렇듯 시스템이 클수록, 관계자들은 통일된 하나의 모델을 만드는 것이 어려워 진다. 따라서 DDD에서는 바운디드 컨택스트를 정의한다.
바운디드 컨텍스트를 통해 의미를 명확하게 하기
바운디드 컨텍스트는 구현상으로 하나의 프로젝트 또는 어플리케이션으로 취급한다. 앞서 시스템의 크기를 작게 유지하기 위한 전략이다.
*모든 바운디드 컨텍스트가 DDD로 구현될 필요는 없다.
바운디드 컨텍스트는 모델의 경계를 결정하며 한 개의 바운디드 컨텍스트는 논리적으로 한 개의 모델을 갖는다.
이상적으로는 하위 도메인과 바운디드 컨텍스트가 1:1 관계를 가지면 좋겠지만, 현실은 기업의 팀 조직 구조로 인해 나눠지기도 하고 용어를 명확하게 구분하지 못해 두 하위 도메인을 하나의 바운디드 컨텍스트에서 구현하기도 한다.
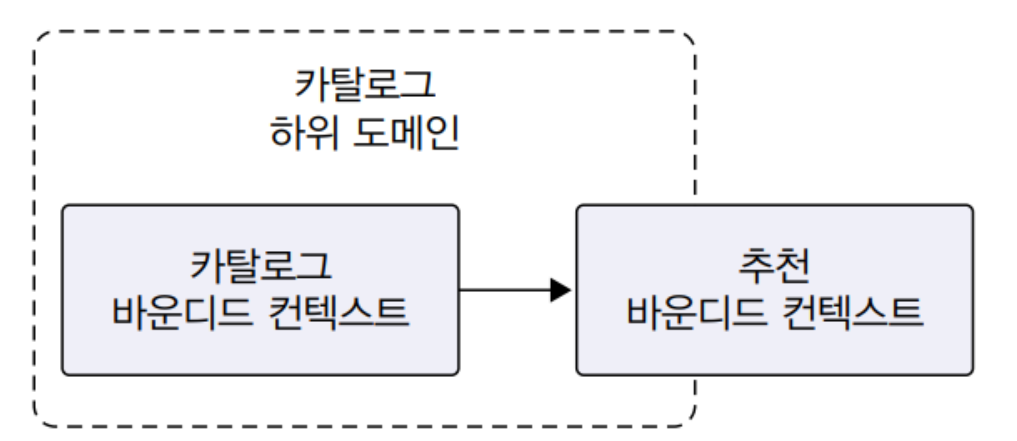
바운디드 컨텍스트 간 통합
온라인 쇼핑 사이트에서 추천 시스템을 추가한다고 가정하자. 그리고 이를 위해서 새로운 팀이 꾸려졌다. 그럼 다음과 같이 바운디드 컨텍스트가 생긴다.
이제 두 바운디드 컨텍스트를 개발하기 위해 자연스럽게 바운디드 컨텍스트간 통합이 발생한다.
사용자가 제품 상세페이지를 볼 때, 보고 있는 상품과 유사한 상품 목록을 하단에 보여준다는 기능을 고민해보자. 이를 위해서 가장 먼저 생각할 수 있는 방법은 REST API를 사용하는 방법이다. 이는 두 바운디드 컨텍스트를 직접 통합하는 방식이다.
두 바운디드 컨텍스트를 간접적으로 통합하는 방법도 있다. 바로 메시지 큐를 사용하는 것이다.
그럼 비동기로 메시지를 처리하기 때문에 카탈로그 바운디드 컨텍스트는 메시지를 큐에 추가한 뒤 응답을 기다리지 않고 다른 작업을 마무리할 수 있다.
메시징 시스템을 사용하려면 데이터 형식을 맞춰야 한다. 이때 카탈로그 입장에서 데이터 구조를 만들지, 추천 입장에서 데이터 구조를 만들지 결정해야 한다.
카탈로그 도메인 관점 VS 추천 도메인 관점
이때 추천 도메인 관점에서 데이터 구조를 짜면 REST API를 사용해서 데이터를 전달하는 것과 차이가 없다.
컨텍스트 맵
개별 바운디드 컨텍스트에 매몰되면 전체를 보지 못할 때가 있다. 이를 방지하기 위해 컨텍스트 맵을 만들기도 한다. 이때 바운디드 컨텍스트의 주요 애그리거트를 함께 명시하면 더 좋다.
*OHS(오픈 호스트 서비스): 상류 팀의 고객인 하류 팀이 다수 존재할 때 상류 팀에서 하류 팀의 요구사항을 수용할 수 있는 API를 만들고 이를 서비스 형태로 공개하여 일관성을 유지할 수 있게 하는 서비스
*ACL(안티럽션 계층): 모델 변환을 처리
이벤트
이벤트가 필요한 상황을 위해 몇 가지 가정을 해보자.
쇼핑몰 주문 취소
외부 시스템(PG사)를 통해 환불을 진행해야 한다.
환불이 진행되면 이메일을 발송해야 한다.
API로 찔렀을 경우 문제점
외부 시스템이 불안정하여 응답이 늦을 수 있다.
PG사의 장애가 우리의 장애로 이어질 수 있다.
외부 시스템이 실패해도 주문 취소는 정상적으로 작동해야 한다.(나중에 환불을 재시도 한다.)
주문 취소와 환불은 서로 다른 트렌젝션으로 실행되어야 한다.
주문 도메인의 로직에 결제 로직(API 호출로직)이 섞일 수 있다. 또한 이메일 발송 로직도 마찬가지이다.
이 모든 문제는 시스템 사이의 강 결합 때문이다. 이를 해결하는 방법이 바로 이벤트다.
이벤트 개요
이벤트란 과거에 벌어진 어떤 것을 의미한다. 그리고 이 이벤트의 발행을 기준으로 다른 작업들을 수행할 수 있다. (JS의 이벤트를 생각하면 편하다)
이벤트는 크게 2가지 용도로 사용된다.
트리거
도메인의 상태가 변경되면 후 처리를 수행한다.
SMS 발송 등이 있다.
서로 다른 시스템 간의 데이터 동기화
주문 도메인에서 배송지를 변경하면 외부 배송 서비스와 배송지 정보를 동기화할 수 있다.
비동기 이벤트 처리
회원 가입 검증 이메일은 즉시 발송될 필요 없다. 10초 후여도 괜찮다. 심지어 이메일을 받지 못하면 재전송 할 수도 있다. 이를 위해 비동기 이벤트 처리를 사용할 수 있다.
이벤트를 비동기로 구현하는 방법은 다양한데, 그 중 네 가지 방식을 살펴보자
로컬 핸들러를 비동기로 실행하기
메시지 큐를 사용하기
이벤트 저장소와 이벤트 포워더 사용하기
이벤트 저장소와 이벤트 제공 API 사용하기
로컬 핸들러 비동기 실행
이벤트 핸들러를 별도 스레드로 실행하는 방법이다. Spring에서는 간단하게 @Async만 붙이면 된다.
메시징 시스템을 이용한 비동기 구현
Kafka나 RebbitMQ를 활용하는 방법이다.
필요하다면 이벤트를 발생시키는 도메인 기능과 메시지 큐에 이벤트를 저장하는 절차를 한 트랜잭션으로 묶어야 한다. 이는 글로벌 트렌젝션으로 수행한다.
MQ를 사용하면 이벤트 발행과 핸들러가 다른 JVM에서 이루어진다.
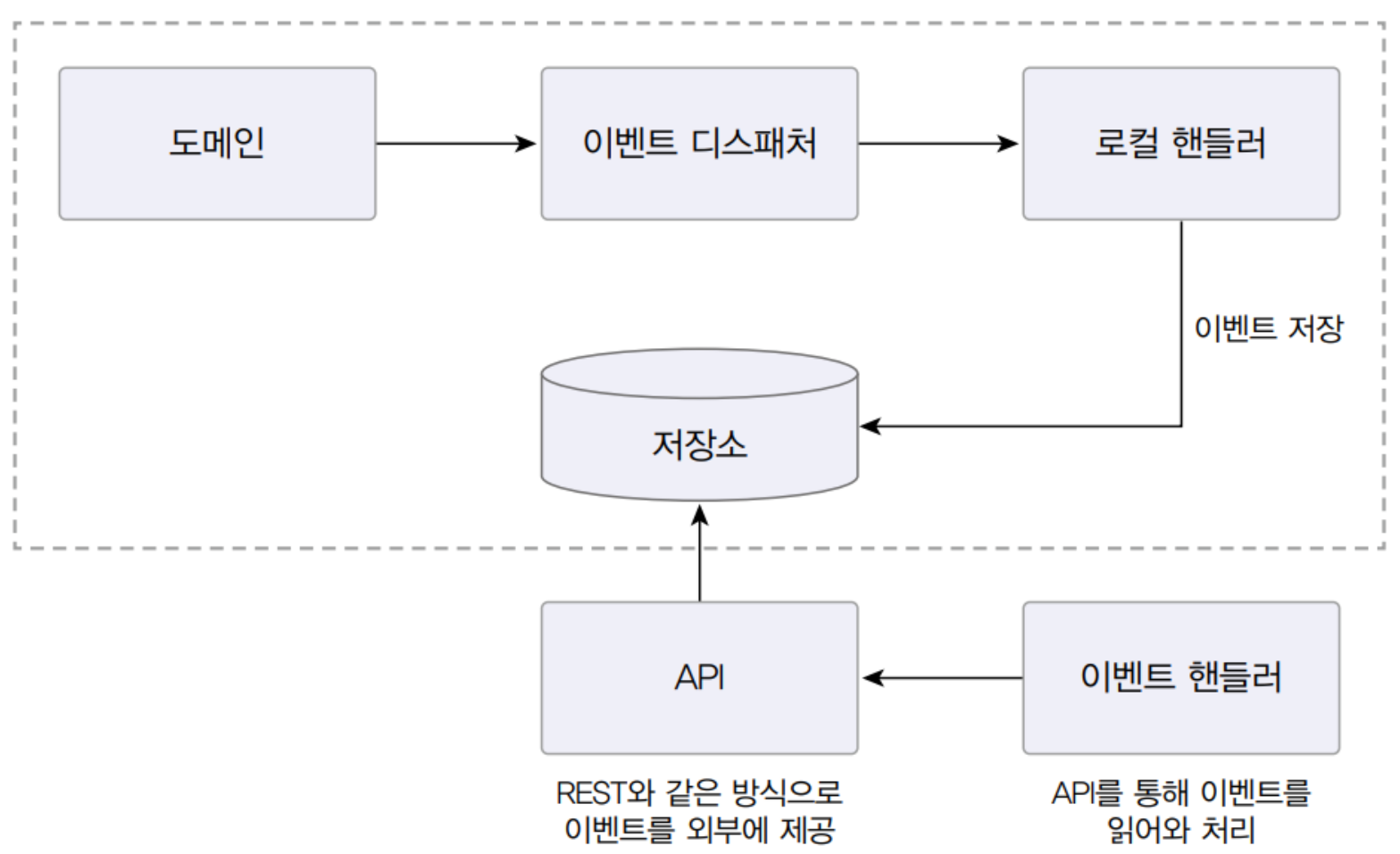
이벤트 저장소를 이용한 비동기 처리
이 방식은 이벤트를 일단 DB에 저장한 뒤 별도 프로그램을 이용해서 이벤트 핸들러에 전달하는 것 이때 저장소에서 이벤트를 읽도록 하는 주체가 누구인지에 따라 포워드 방식과 API방식으로 나뉜다.
CQRS
앞서 언급한 다른 애그리거트를 식별자로 참조하는 방식은 성능 이슈가 있다. 또한 도메인 상태 변경 에 적합한 ORM 기능으로 조회를 구현하는 것은 구현을 복잡하게 만드는 원인이 된다. 이를 해결하기 위해 CQRS를 도입한다.
필요에 따라서는 명령과 조회를 다른 저장소를 사용할 수 있다. 이를 위해 일반적으로 명령은 OLTP 저장소를, 조회는 OLAP저장소를 사용하곤 한다. 그리고 두 저장소를 동기화 하기 위해 앞서 배운 이벤트를 활용한다.
앞선 글에서 언급한 바와 같이 리포지터리 인터페이스는 domian영역에, 구현은 infra 영역에 속한다. JPA를 활용하면 기본적으로 두 가지 메서드를 제공한다.
Optional<Order> findById(OrderNo no)
void save(Order order)
이때 JPA는 변경 감지 기능을 활용해서 Entity를 영속화 시킬 수 있기 때문에, 따로 저장 쿼리를 날려줄 필요는 없다. 또한 Optional을 사용해서 조회 결과가 null인 경우를 우아하게 처리할 수도 있을 것이다.
이렇게 기본 메서드를 만들고, 이후에 필요에 따라 추가 메서드를 구현하게 된다. 예컨데 findByOrdererId, delete와 같은 것이다.
*사실 Entity를 delete하는 요구 사항이 있더라도 데이터를 실제로 삭제하는 경우는 많지 않다. 데이터 삭제보다는 플래그를 이용해 사용자에게 보여줄지 여부를 결정하는 것이 일반적이다.
스프링 데이터 JPA를 이용한 리포지터리 구현
Spring Data Jpa는 인터페이스만 만들면 구현체를 자동으로 만들어서 Spring Bean으로 등록해준다. Spring Data Jpa는 필자가 이미 익숙하므로 생략하겠다.
매핑 구현
애그리거트와 JPA 매핑을 위한 기본 규칙은 다음과 같다.
애그리거트 루트는 @Entity로 매핑 설정한다.
밸류는 @Embeddable로 매핑 설정한다.
밸류 타입 프로퍼티는 @Embedded로 매핑 설정한다.
이런 규칙을 따라서 매핑하면 아래의 그림과 같은 형태로 매핑 되게 된다. 그림을 보면 알겠지만, 밸류 타입은 엔티티와 한 테이블에 표현되는 경우가 많다.
@Embeddable, @Embedded의 사용법은 익숙하니 넘어가고, @AttributeOverride 에너테이션에 대해 간단히 살펴보자.
위의 그림에서 보면 Address밸류에 있는 필드가 실제 테이블과 이름이 다르다. 이럴 때 사용하는 것이 @AttributeOverride 에너테이션이다.
이런 식으로 사용하는 것이다.
기본 생성자
엔티티와 밸류의 생성자는 객체를 생성할 때 필요한 것을 전달 받는다. 이때 불변 타입이면 생성 시점에 필요한 값을 모두 전달 받으므로, set 메서드가 필요없다. 하지만 JPA에서 @Entity와 @Embeddable을 매핑하려면 기본 생성자를 제공해야 한다. 이는 바이트 코드를 조작해서 객체를 만드는 CGLIB의 특성 상 어쩔 수 없는 부분이다.
이런 기술적인 이유로 우린 반드시 기본 생성자를 만들어야 하지만, 외부에서 이를 사용하는 것은 막아야 한다. 따라서 public이 아니라 protected로 선언해야 한다.
필드 접근 방식 사용
protected 기본 생성자를 통해서 Entity/Value 객체를 생성했다면, 이제 객체의 필드와 테이플의 컬럼을 매핑 해줘야 한다. 이때 필드와 메서드 2가지의 매핑 방법이 있다.(아니 전혀 몰랐는데?)
이는 @Access 어노테이션으로 지정해 줄 수 있는데, 다음과 같이 사용하게 된다.
이 방식은 Method를 통해서 매핑 하는 방법이다. 클래스 위에 @Access(Accesstype.PROPERTY)를 달아주는 것으로 메서드 매핑 방법을 실현할 수 있다. 이 방법은 캡슐화를 깨고, 엔티티 밖에서 핵심 도메인 로직을 수행할 가능성을 만든다. 또한 밸류 타입의 경우 불변성을 유지하지 못하게 되는 문제가 발생하게 된다. 따라서 우리는 메서드 매핑 방식이 아니라 필드 매핑 방식을 사용할 것이다.
@Access(AccessType.FIELD)를 달아줘서 필드 매핑을 했다. 우리에게 친숙한 방법으로, 필드 위에 어노테이션을 달아서 매핑에 대한 자세한 정보를 기술한다.
필자가 JPA를 사용하는동안 이런 방식이 있는지 왜 알지 못했을까?
그 이유는 바로 @Access를 설정하지 않으면 @Id나 @EmbeddedId의 위치를 기준으로 접근 방식이 설정되기 때문이다. @Id가 필드에 달려 있으면 필드 접근, Getter에 달려 있으면 프로퍼티 접근 방법을 사용하게 된다.
AttributeConverter를 이용한 밸류 매핑 처리
두 개 이상의 프로퍼티를 가진 밸류 타입을 한 개 칼럼에 매핑 하려면 @Embedddable 애너테이션이 아니라 @AttributeConverter 애너테이션을 사용해야 한다.
예컨데, Length라는 밸류객체가 2개의 프로퍼티를 갖고 있는데 DB 테이블에는 한 개 칼럼으로 표현되는 경우가 있을 수 있다.
7
이럴 때 AttributeConverter 인터페이스를 상속 받아서 구현함으로서 활용할 수 있다.
이렇게 생긴 인터페이스를
이렇게 구현하는 것이다.
두 메서드의 이름을 보면 각각이 어떤 역할을 수행할지 명확히 보인다.
여기서 @Converter 애너테이션을 주목하자. autoApply 속성을 true로 주면 이제 자동으로 해당 밸류 객체를 변환해서 반환해 준다. 만약 autoApply 값을 false로 주게 된다면(default가 false이다.) 프로퍼티 값을 변환할 때 사용할 컨버터를 직접 지정해야 한다.
밸류 컬렉션: 별도 테이블 매핑
Order Entity와 OrderLine을 생각해보자. Order은 여러 개의 OrderLine을 가질 수 있다. 그리고 OrderLine은 밸류 객체이다. 이럴 때 우리는 List 타입의 콜랙션을 @ElementCollection과 @CollectionTable을 함께 사용해서 매핑 할 수 있다.
이 방식은 평소에 전혀 사용해보지 않은 방식이다. 이는 밸류 타입과 엔티티 타입을 명확히 분리하지 않고 개발했던 나의 습관 때문일 것이다.
그래서인지 한 가지 의문이 생겼다. @OneToMany와 @ElementCollection의 차이는 뭘까?
이는 @ElementCollection을 사용한 밸류 타입 객체는 부모 엔티티와 독립적으로 존재할 수도, 쿼리할 수도, 생존할 수도 없다는 것이다. 따라서 캐스케이드 작업을 전혀 지원하지 않으며, 이는 해당 객체가 항상 부모 엔티티와 함께 유지, 병합, 제거됨을 의미한다. 특히 개념적으로 이 객체는 밸류 타입이라는 것을 명시하는 것과 같은 효과를 기대할 수 있을 것이다.
벨류 컬렉션: 한개 칼럼 매핑
밸류 컬렉션을 별도의 테이블이 아닌 하나의 컬럼에 저장해야 하는 경우도 분명히 있을 것이다. 예를 들어서 사용자의 주소를 별도의 테이블로 저장하는 것이 아니다 Comma(,)를 통해서 분리만 해두는 것이다. 이를 위해서도 앞서 설명한 AttributeConverter를 사용할 수 있을 것이다. 단 AttributeConverter를 사용하려면 밸류 컬렉션을 표현하는 새로운 밸류 타입을 추가해야 한다.
이렇게 해야 AttributeConverter의 제네릭(generalize)에 담을 수 있다.
밸류를 이용한 ID 매핑
식별자를 지정할 때는 밸류 객체를 만들어서 @id 대신 @EmbeddedId를 사용하자. 밸류 타입을 사용하면 ID를 표현한 밸류 객체 내부에 도메인 로직을 추가할 수 있다. 예컨데, Snowflake 방식으로 만들어진 ID에서 시간을 추출하거나, 요청이 처리된 Server를 확인할 수 있는 메서드를 추가할 수 있을 것이다.
별도 테이블에 저장하는 밸류 매핑
애그리거트에서 루트를 제외한 구성요소는 대부분 밸류이다. 루트 외에 또 다른 엔티티가 있다면 밸류이거나 다른 애그리거트에 속할 확률이 높다.
애그리거트에 속한 객체가 밸류인지 엔티티인지 구분하는 방법은 고유 식별자를 찾는 것이다. 이때의 식별자는 객체를 유일하게 식별하기 위해서 사용되는 것을 의미한다. 테이블에 존재하는 식별자가 고유 식별자가 아닐 수 있다. 이는 단지 매핑을 위한 장치일 수 있는 것이다.
예를 들어보자.
Article 객체에서 ArticleContent 객체를 분리했다. 그리고 ID가 존재하길래 이를 Entity로 생각해서 @OneToOne Mapping했다. 하지만 이는 잘못됐다. ArticleContent의 ID는 Article 테이블의 데이터와 연결하기 위한 것이지, ARTICLE_CONTENT를 위한 별도 식별자가 필요한 것은 아니었다. ArticleContent를 밸류로 보고 접근하면 모델은 다음과 같이 바뀐다.
ArticleContent는 밸류이므로 @Embeddable로 매핑한다. 하지만 이 방식은 앞서 살펴본 바와 같이 새로운 테이블로 매핑되지 않고, Article 테이블 컬럼들이 포함되게 된다. 이를 방지하기 위해서 @SecondaryTable과 @AttributeOverride를 사용해야한다.
@SecondaryTable과 @AttributeOverride의 자세한 문법은 글의 분량 상 생략한다. 관심 있는 사람들은 검색해보자.
이렇게 하나의 엔티티에 여러 테이블을 매핑하면 조회 성능이 떨어지는 문제가 있다. 엔티티 루트를 조회하면 언제나 SecondaryTable을 Join해서 가져오기 때문이다. 이를 해결하는 방법으로 5장에서 조회 전용 기능 구현을 살펴보고, 11장에서 Query/Command 분리 기법을 알아본다.
밸류 컬렉션을 @Entity로 매핑하기
개념적으로는 벨류인데, 구현 기술이나 팀 표준 때문에 @Entity를 사용해야 할 때도 있다.
만약 업로드 방식에 따라 썸네일 저장 여부와 URL을 구성하는 방식이 변경된다면 상속을 이용해서 도메인 모델을 만들 것이다. 그리고 각 메서드를 다형성을 이용해서 효과적으로 핸들링 할 것이다. 하지만 슬프게도 JPA에서 밸류 타입은 상속 매핑을 지원하지 않는다. 이를 해결하기 위해 @Embeddable 대신@Entity를 사용해서 상속 매핑을 해야 한다. 그리고 테이블에서는 DTYPE(discriminator type)을 통해서 타입을 식별한다.
한 테이블에 Image와 그 하위 클래스를 매핑 하기 위해 다음과 같은 설정이 필요하다.
@Inheritance 애너테이션 적용, strategy 값으로 SINGLE_TABLE 사용
상속을 매핑 하는데, 한 테이블에 저장하는 방식으로 하겠다는 의미
@DiscriminatorColumn 애너테이션을 이용하여 타입 구분 용으로 사용할 칼럼 지정
상속 받은 클래스에 @DiscriminatorValue 애너테이션을 달아 줘야 함
그리고 Image를 Entity로 매핑했지만 모델에서 Image는 밸류 이므로 상태를 변경할 수 없도록 해야한다.
Image는 밸류이므로 라이프 사이클을 PRODUCT에 완전히 의존한다. 따라서 cascade와 orphanRemoval을 잘 설정해줘야 한다.
또한 Hibernate의 경우 @OneToMany 로 매핑된 컬렉션의 clear() 매서드를 호출하면 삭제 과정이 비효율 적이다(Query를 여러 번 날린다).
반면 @Embeddable로 이를 매핑하면 단일 클래스에 DTYPE만 다르게 해서 구현해야 한다. 이렇게 된다면 각 메서드는 분기 처리를 통해서 수행해야 할 것이다.
이 두 가지 방법은 분명 트레이드-오프가 존재한다. 따라서 유지 보수와 성능 두 가지 측면을 고려해서 구현 방식을 선택해야 한다.
ID참조와 조인 테이블을 이용한 단 방향 M-N 매핑
앞서 한 애그리거트에서 다른 애그리거트의 집합 연관을 성능 상의 이유로 피하라고 조언했지만, 상황에 따라 어쩔 수 없는 경우도 존재한다. 이런 경우 ID 참조를 이용한 단 방향 집합 연관을 적용해볼 수 있다. 이는 3장에서 이미 보여준 바 있다.
애그리거트 로딩 전략
애그리거트에 속한 객체는 모두 모여야 완전한 하나가 된다. 그리고 이는 애그리거트에 속한 모든 객체가 즉시 로딩 전략을 취해야 한다는 것으로 받아 들여지기 쉽다. 하지만 이는 성능 문제를 가져오기도 한다. 특히 카사디안 곱으로 JOIN이 걸리는 경우가 대표적이다. 따라서 저자는 지연 로딩 전략을 고려할 것을 제안한다.
우리가 애그리거트를 완전하게 유지하려는 이유는 2가지 이다.
상태를 변경하는 기능을 실행할 때 애그리거트 상태가 완전해야 한다.
표현 영역에서 애그리거트의 상태 정보를 보여줄 때 필요하다.
이 2가지 이유 중에 2번째 문제는 별도의 조회 전용 기능과 모델을 구현하는 방식을 사용하는 것이 더 유리하기 때문에, 근본적인 이유는 애그리거트의 상태 변경과 관련된 1번째 문제가 더 크다. 하지만 상태 변경을 위해 즉시 로딩이 필수적이지는 않다. 트랜잭션 범위 내에서의 지연 로딩은 허용되기 때문이다. 또한 이로 인해 발생하는 추가 쿼리의 양도 조회 쿼리에 비해 현저히 적을 것으로, 상태 변경 쿼리의 지연 로딩이 주는 성능 저하는 치명적이지 않는다.
지연 로딩은 동작 방식이 모든 JPA의 구현체에 동일하고, 즉시 로딩처럼 다양한 경우의 수를 따질 필요도 없는 장점이 있다. 하지만 쿼리 실행 횟수가 즉시 로딩 보다 많아질 확률이 높다는 것 역시 사실이다. 결국 상황에 따라 즉시 로딩과 지연 로딩을 잘 선택 해야 한다.
애그리거트의 영속성 전파
애그리거트는 조회/수정/삭제 등 모든 상황에서 완전한 상태여야 한다.
저장 메서드는 애그리거트 루트 뿐만 아니라 애그리거트에 속한 모든 객체를 저장한다.
삭제 메서드는 애그리거트 루트 뿐만 아니라 애그리거트에 속한 모든 객체를 삭제한다.
@Embeddable 매핑 타입은 함께 저장 및 삭제가 가능하지만, @Entity 타입으로 매핑한 경우에는 cascade 속성을 사용해서 완전한 상태를 유지해 줘야 한다.
식별자 생성 기능
식별자는 크게 3가지 방법으로 만들어진다.
사용자가 직접 생성 (ex_이메일 등)
도메인 로직으로 생성 (ex_snowflake 등)
DB를 이용한 일련번호 사용 (ex_Identity방식 등)
사용자가 직접 생성하는 경우는 프로그램에 식별자 생성 기능을 구현할 필요가 없다.
도메인 로직으로 생성하는 경우는 별도 서비스로 식별자 생성 기능을 분리해야 한다. 그리고 식별자 생성 기능은 도메인 로직이기 때문에 도메인 영역(도메인 서비스)에 위치 시켜야 한다.
DB를 이용해서 생성하는 경우에는 JPA의 @GeneratedValue를 사용하게 된다. 이때 저장 ID를 저장 시점에 알 수 있다는 점을 유의해서 개발해야 한다.
도메인 구현과 DIP
이번 장에서 논의했던 도메인 구현 방식은 DIP 원칙을 어기고 있다. @Entity, @Talbe, @Id, Respotiroy<T, K> 등 도메인이 인프라에 의존하고 있다.
그럼 의존을 제거하고 순수한 도메인 모델을 만든다면 어떤 모양이 되어야 할까?
이런 구조가 된다. 이렇게 된다면 Infra를 구현 기술을 언제든 변경할 수 있을 것이다.
하지만 저자는 infra 구현 기술은 거의 변경되지 않고, DIP를 지키면 필요 이상으로 구현이 복잡해 지는 점을 지적한다. 또한 도메인 모델을 단위 테스트하는데 문제가 없다는 점 역시 언급했다.
DIP를 완벽하게 지키면 좋겠지만, 개발 편의성과 실용성을 가져가면서 구조적인 유연함은 어느 정도 유지하는 것이 합리적 선택이다.
도메인 객체 모델이 복잡해 지면 전반적인 구조나 큰 수준에서 도메인 간의 관계를 파악하기 어려워 진다. 이럴 때 상위 수준에서 모델을 이해해야 전체적인 구조를 유지한 채로 코드를 추가/변경할 수 있다. 이때 사용하는 개념이 애그리거트이다.
아래의 사진을 보면 복잡하게 엔티티와 벨류가 흩어져 있다.
이를 애그리거트로 묶으면 도메인을 단순하게 만들어서 이해하고 관리하기 쉬워진다.
한 애그리거트에 속한 객체는 유사하거나 동일한 라이프 사이클을 갖는다. 예를들어 주문 애그리커트를 만들려면 Order, OrderLine, Orderer와 같은 관련 객체를 함께 생성한다. 또한 ShippingInfo는 만들었지만 Order는 만들지 않는 일은 없다.
애그리거트는 명확한 경계를 가진다. 각각의 애그리거트는 자기 자신을 관리할 뿐 다른 애그리거트를 관리하지 않는다. 그런데 직접 구조를 만들다 보면 경계를 설정하는 것이 항상 어렵다. 저자는 경계를 만드는 규칙을 설명한다. 도메인 규칙에 따라 함께 생성되는 요소는 같은 애그리거트일 확률이 높고, 사용자 요구사항에 따라 함께 변경되는 요소도 같은 애그리거트일 확률이 높다.
A가 B를 갖는다로 설계되는 요구사항이 있어도 같은 애그리거트가 아닐 수 있다. 좋은 예시가 Product와 Review이다. 이 둘은 한 애그리거트 처럼 보이지만, 함께 생성되거나 변경되지 않는다. 게다가 Product를 변경하는건 상품 담당자지만, Review를 생성하고 변경하는건 고객이다.
처음 도메인 모델을 만들기 시작하면 큰 애그리거트로 보인 것들이 많지만, 경험이 쌓이면 애그리거트는 점점 작아진다. 작가는 애그리거드가 하나의 엔티티 객체만 갖는 경우가 많았으며, 두개 이상의 엔티티로 구성되는 경우는 드물다고 언급한다.
애그리거트 루트
애그리거트 루트는 애그리거트에 속한 모든 객체가 일관된 상태를 유지할 수 있도록 애그리거트 전체를 관리한다.
애그리거트 루트의 핵심은 일관성이다. 이를 위해서 애그리거트 루트는 도메인 기능을 구현한다. 프로그래밍을 하면서 경험적으로 대부분 알고 있겠지만, 상태를 변경하는 지점을 한군데로 모았을 때 우리는 일관성을 더 잘 유지할 수 있다. 이는 애그리거트 루트에서 일관성을 철저하게 지켰을 때에 유효한 명제이다. 애그리거트 루트에서 일관성을 유지하려면 2가지를 습관적으로 적용해야 한다.
set method는 private으로 만들 것
벨류는 불변타입으로 만들 것
애그리거트 루트의 기능 구현 애그리거트 루트가 구성요소의 상태만 참조해서 모든 로직을 수행하는 것은 아니다. 일부의 기능 실행은 위임하기도 한다.
트랜젝션 범위는 작을 수록 좋다. 그리고, 한 트랜젝션에서는 한 애그리거트만 수정해야 한다. 애그리거트는 서로 독립적인데, 같은 트랜잭션으로 묶이게 되면 결합도가 높아진다. 이는 향후 수정비용의 증가로 이어지므로, 애그리거트는 다른 애그리거트의 상태를 변경하지 말아야 한다. 부득이하게 두 애그리거트를 수정해야 한다면 애그리거트에서 직접 수정하지 말고 어플리케이션에서 수정하자.
리포지토리와 애그리거트
애그리거트는 개념적으로 하나이므로, 애그리거트에 속하는 엔티티와 벨류는 원자적으로 저장되거나 롤백되어야 한다. RDBMS는 트렌젝션을 통해 이를 보장할 수 있고, 몽고DB와 같은 저장소는 한 페이지에 전에 애그리거트를 저장하는 방식으로 일관성을 유지할 수 있을 것이다.
ID를 이용한 애그리거트 참조
애그리거트간의 통신은 종종 발생한다. 책에서는 다른 애그리거트를 참조할 때 ID를 통해서 조회하는 방식을 제안한다.
지금까지는 특정 엔티티가 다른 엔티티를 참조할 때 @OneToMany와같은 매핑 함수를 활용했다. 하지만 이는 다음과 같은 문제를 야기할 수 있다.
편한 탐색 오용
성능에 대한 고민
확장 어려움
이중 작가는 가장 큰 문제로 편한 탐색 오용을 지적한다. 쉬운 탐색은 한 애그리거트가 다른 애그리거트의 상태를 쉽게 변경하도록 한다. 이는 앞서 언급한 트렌젝션의 범위를 넓힌다는 문제도 있고, 엔티티의 생명주기를 다른 엔티티에게 위임하는 꼴이 될 수도 있다. 또한 직접참조는 애그리거트간의 의존 결합도를 높여서 결과적으로 애그리거트의 변경을 어렵게 만든다.
두 번째 문제는 애그리거트 직접 참조는 성능과 관련된 여러 고민을 해야 한다는 것이다. Lazy로딩과 Eager로딩을 고민하는 등, 프로그램을 복잡하게 한다.
마지막은 확장의 어려움이 있다. 초기에는 단일 서버, DBMS를 활용하지만 트레픽이 많아지만 도메인별로 시스템을 분리(Micro Service)하게 된다. 그리고 이때 서로다른 DBMS를 활용하게 되면 더이상 JPA와 같은 단일 기술을 사용할 수 없음을 의미한다.
이러한 문제를 회피하기 위해 작가는 ID를 이용한 애그리거트 참조를 제안한 것이다. 하지만 이 글을 읽는 대부분이 ID참조를 선택하면 성능을 포기해야 하는것이 아니냐는 의문이 들 수 있다.
ID참조의 성능문제에 대한 해결책으로 작가는 조회 전용 쿼리를 사용하는 것을 추천한다. 이는 따로 DAO객체를 만들어서 조회 메서드에서 조인을 이용해 한 번의 쿼리로 필요한 데이터를 로딩하는 방법을 말한다.
만약 애그리거트마다 서로 다른 저장소를 사용하면 한 번의 쿼리로 관련 애그리거트를 조회할 수 없다. 이럴때는 캐시나 조회 전용 저장소를 따로 구상해야 한다. 이 방법은 코드가 복잡해지는 단점이 있지만, 시스템의 처리량을 높일 수 있다는 장점이 있다.
애그리거트 간 집합 연관
애그리거트간에 M:N, 1:N, N:1등의 관계를 가질 수 있다. 이때 요구사항을 잘 확인해서 연간관계를 설정해야 한다. 우리는 의존성을 최소화하고 복잡하고 어려운 코드와 성능 문제를 최대한 회피해야 한다. 이를 위해서 필요 없는 의존을 없애야 한다. 예컨데, 카테고리와 상품 목록을 M:N으로 모델링 했다고 해도 카테고리별 상품을 조회할 때 해당 상품이 가지고있는 모든 카테고리를 보여주지 않는다. 모든 카테고리를 보게 되는 것은 상품의 세부 화면이다. 즉, 개념적으로는 상품과 카테고리의 양방향 M:N 연관이 존재하지만 실제 구현에서는 상품에서 카테고리로의 단방향 M:N 연관만 적용하면 되는 것이다.
*@ElementCollection이라는 어노테이션으로 JPA에서 Value Collection을 구현할 수 있다. 예컨데 Product에서 Set<CategoryId> categoryIds라는 변수를 통해 1:N 관계를 구현하려면 @ElementCollection을 사용할 수 있는 것이다.
애그리거트를 팩토리로 사용하기
애그리거트가 갖고있는 데이터를 이용해서 다른 애그리거트를 생성해야 한다면 애그리거트에 팩토리 메서드를 구현하를 것을 고려해보자. 예를 들어 신고당한 Store는 Product을 등록할 수 없다는 규칙이 생겼다고 가정해보자. 그럼 응용 서비스에서 해당 Store가 유효한지 확인하고 Product를 만들 것이다. 하지만 이 방식은 중요한 도메인 로직처리가 응용 서비스에 노출되게 된다. 이를 해결하기 위해서 Store객체에 createProduct 메서드를 추가해서 유효성 검사를 하게 하면 응집력이 높아진다.
Chapter 1_도메인 모델 시작하기:https://inhyeok-blog.tistory.com/55 Chapter 2_아키텍처 개요 : https://inhyeok-blog.tistory.com/56 Chapter 3_애그리거트 : Chapter 4_리포지터리와 모델 구현 : Chapter 5_스프링 데이터 JPA를 이용한 조회 기능 : Chapter 6_응용 서비스와 표현 영역 : Chapter 7_도메인 서비스 : Chapter 8_애그리거트 트랜잭션 관리 : Chapter 9_도메인 모델과 바운디드 컨텍스트 : Chapter 10_이벤트 : Chapter 11_CQRS :
이러한 아키텍처는 아주 익숙하다. 기존에 사용하던 Controller-Service-Repository(표현-응용-인프라)로 이어지는 흐름과 비슷하다. 다만 여기서 도메인이 Data Object에서 그치지 않고 비즈니스 로직을 수행하는 하나의 계층으로 떠오른 것뿐이다. 그리곤 응용(Application)에서는 대부분의 기능을 도메인에게 위임한다.
앞서 보여준 구조는 이 그림과 같은 계층구조를 가지고 있다. 그리고 계층구조의 특성상 상위 계층은 하위계층을 의존하지만(구현의 편의를 위해 응용이 인프라를 의존하기도 한다), 하위 계층은 상위 계층을 모른다. 이 방식은 상위 계층이 하위계층의 구현에 의존한다는 것을 의미한다(즉, 인터페이스가 아니라 클래스에 의존한다). 그 이유는 하위계층의 인터페이스는 상위계층에 속하기 때문인데, 이에 대한 자세한 설명은 아래에서 설명하겠다. 하지만 이러한 방식은 두 가지 문제점을 가진다.
의존하는 하위 계층의 객체가 구현되기 전까지 상위 계층의 객체를 테스트하기 어렵다.(테스트의 어려움)
구현 방식을 의존하기 어렵다.(기능확장의 어려움)
이를 해결하기 위해서 DIP(Dependency Inversion Principle)를 소개한다.
바로 이렇게 하면 된다. 이것이 바로 DIP, 즉, 의존 역전 원칙이다. 이제 DIP를 통해서 앞서 말한 두 가지의 문제를 해결할 수 있다. 이때 주의해야 할 점이 있다. 바로 Interface만 만든다고 다 저수준이 되는 것은 아니라는 것이다. 인터페이스를 도출할 때 고수준의 DroolsRuleDiscounter의 관점에서 도출하는 것이 아니라, CalculateDiscountService에서 메시지 목록을 추출하는 것이 중요하다.
이제 도메인 영역의 주요 구성요소를 살펴보자.
엔티티(ENTITY)
고유 식별자를 갖는 객체로, 자신의 라이프 사이클을 갖는다.
도메인의 고유한 개념을 표현한다.
도메인 모델의 데이터를 포함하며 해당 데이터와 관련된 기능을 제공한다.
벨류(VALUE)
식별자를 가지지 않는다.
개념적으로 하나인 값을 표현할 때 사용된다.
엔티티의 속성뿐만 아니라 다른 벨류의 속성이 될 수도 있다.
애그리거트(AGGREGATE)
연관된 엔티티와 밸류 객체를 개념적으로 하나로 묶은 것이다.
속한 객체들이 동일한 라이프 사이클을 가진다.
리포지터리(REPOSITORY)
도메인 모델의 영속성을 처리한다.
도메인 서비스(DOMAIN SERVICE)
특정 엔티티에 속하지 않은 도메인 로직을 제공한다.
인프라스트럭처는 표현 영역, 응용 영역, 도메인영역을 지원한다. 그리고 앞서 말한 것 처럼 DIP를 활용해서 테스트의 어려움과 기능 확장의 어려움을 해결할 수 있었다. 하지만 인프라스트럭처를 활용하는 모든 상위 계층 객체가 완벽히인프라스트럭처의 구현에 의존하지 않도록 하겠다는 생각은 적절하지 않다. 이는 자칫 구현을 더 복잡하고 어렵게 만들 수 있기 때문이다. 가장 대표적이 예시가 바로 @Table, @Transactional 등의 어노테이션이다. 스프링에 대한 의존을 없애려면 복잡한 스프링 설정을 사용해야 한다.
이제 도메인 주도 개발을 했을 때의 모듈 구성을 살펴보자. 기본적으로 애그리거트별로 모듈을 만들고 하위 모듈로 UI(표현)-application(응용)-domain(도메인)-infrastructure(인프라)로 나눈다.
각 도메인 안에 하위 도메인을 하위 모듈로 둘 수도 있고, Command와 Query를 분리하기도 하는 등 다양한 확장요소가 있다.
하지만 자세한 내용을 코드를 보면서 이해하는 것이 가장 빠르므로, 마지막으로 이 책에서 설명하는 코드가 들어있는 GIthub Repositorty를 공유하고 글을 마친다. 모듈은 잘 만들어진 예시를 보면서 이해하는 것이 가장 효과적일 것이다.
Chapter 1_도메인 모델 시작하기: https://inhyeok-blog.tistory.com/55 Chapter 2_아키텍처 개요 : Chapter 3_애그리거트 : Chapter 4_리포지터리와 모델 구현 : Chapter 5_스프링 데이터 JPA를 이용한 조회 기능 : Chapter 6_응용 서비스와 표현 영역 : Chapter 7_도메인 서비스 : Chapter 8_애그리거트 트랜잭션 관리 : Chapter 9_도메인 모델과 바운디드 컨텍스트 : Chapter 10_이벤트 : Chapter 11_CQRS :
앞서 「가상면접 사례로 배우는 대규모 시스템 설계 기초」 리뷰를 작성하면서 했던 생각이 '다시는 챕터 별로 리뷰를 포스팅하지 않아야지'라는 것이었다. 그 당시에는 포스터 작성하는 데 걸린 시간이 독서하는 시간만큼(어쩌면 그보다 더) 길었고, 중간에는 목적을 잃어버려서 단지 시작한 일을 끝마야 한다는 의무감으로 키보드를 두들기기도 했다. 하지만 이 책을 처음 펼쳐보고 완전히 생각이 바뀌었다.
분명 난 이 책을 읽은 기억이 없는데 책의 초반부에 밑줄과 필기가 적혀 있는 것이다! 심지어는 친구에게 내가 술을 먹고 책을 읽었던 것 같다는 농을 던지기도 했다. 반면에 「가상면접 사례로 배우는 대규모 시스템 설계 기초」 책에서 배운 지식과 얻은 인사이트는 지금도 머속에 남아서 많은 도움을 주고 있다. 그 이유는 책을 읽은 이후에도 여러 가지 이유로 해당 책에서 읽은 내용을 복기할 일이 많아서도 있지만, 분명히 그때 글을 작성하기 위해서 꼼꼼히 다시 읽어보던 시간이 의미가 있었던 것 같다. 그래서 책을 읽는 현재의 기억을 조금이라도 유지하기 위해서 리뷰를 다시 시작하려고 한다.
그리고 리뷰를 시작하는 한 가지의 이유가 더 있는데, 생각보다 내 글을 읽는 것이 효과적으로 기억을 떠올리게 하고 재밌다는 것이다.
이 두 가지의 목표 달성하기 위해 도서 리뷰를 작성하는 것이기 때문에, 앞으로 진행할 도서 리뷰에서는 조금은 많은 내용을 생략하고 필자의 입맛에 맞게 글을 작성할 계획이다. 이렇게 편한 마음으로 글을 써야 시간을 절약하고 글쓰기를 즐길 수 있게 될 것이다.
우선 작가는 도메인을 소프트웨어로 해결하고자 하는 문제 영역이라고 소개한다. 그리고 이 도메인은 다시 수많은 하위 도메인으로 나뉘어 질 수 있다. 예컨 온라인 서점 시스템은 그 자체로 도메인이지만 하위 도메인으로 주문, 혜택 카탈로그, 리뷰, 정산, 배송, 결제 등등을 가질 수 있다. 이 중에선 개발자가 직접 구현하는 부분도 있을 것이고 외부 시스템의 도움(배달, PG사 결제 등)을 받는 것도 있다. 그리고 도메인 주도 개발은 이 도메인이라는 개념을 가지고 큰 문제를 분할 정복한다.
도메인 모델은 기본적으로 특정 도메인을 개념적으로 표현한 것이다. 이때 객체 기반의 ERD일 수도 있고, State Diagram, Sequence Diagram, 어쩌면 수학적 모델 등이 될 수 있다. 어떤 형식으로 표현하는지는 중요하지 않다. 단지 도메인을 잘 표현할 수 있는 것이 중요한 것이다. 다만 도메인 모델의 종류에 따라서 구현하는 방식이 도메인 모델을 최대한 따라가게 할 수는 있을 것이다.
도메인 모델 패턴은 위에서 보이는 아키텍처 구성에서 도메인 파트에 핵심 규칙을 구현하는 것이다. 특히 비지니스 로직을 객체 지향의 특성을 적극 활용해서 구현한다. 이해를 돕기 위해서 Spring+JPA로 설명하자면, Order라는 Entity 안에 changeShippingInfo() Method를 두는 식이다. 전통적인 레이어드 MVC 모델에서는 도메인을 객체보다는 데이터의 관점으로 바라봤다. 하지만 도메인 주도 개발에서는 도메인을 객체로 바라보고 핵심 규칙을 구현해둔다.
소프트웨어 개발은 요구사항에서부터 시작한다. 그리고 유저 스토리와 같은 요구사항을 대화를 통해 이해하고, 도메인 초안을 만들어야 한다. 예컨데
- 최소 하나 이상의 상품을 주문해야 한다.
- 한 상품을 한 개 이상 주문할 수 있다.
- 출고 전 배송지를 변경할 수 있다.
- 출고 후 배송지를 변경할 수 없다.
- 출고 전 주문을 취소할 수 있다.
- 고객이 결제를 완료하기 전에는 상품을 준비하지 않는다.
등의 요구사항이 있을 수 있다. 이제 이런 요구사항들로부터 도출한 상세 기능을 Order에 Method로 추가할 수 있다.
도메인 모델은 크게 엔티티와 벨류로 구분할 수 있다.
도메인 : 유일한 식별자를 가진다. 그리고 이 식별자는 변하지 않는다.
벨류 타입 : 개념적으로 완전한 하나를 표현할 때 사용된다. 불변성을 가진다.(객체가 변경되면 새로운 객체를 만들어야 한다.) 주소(addr1, addr2, zipCode), 사용자(name, phoneNumber), .돈(money) 등이 있다. 이때 벨류타입은 하나 또는 2개 이상의 속성을 가질 수 있다.
* 벨류 타입이 1개의 속성을 가지는 경우도 포함하는 이유는 Type을 통해 정체를 명확하게 표현하고, 벨류타입의 메소드로 다양한 행위를 정의할 수 있기 때문이다.
* 도메인 모델에서 set을 사용하지 말자. set은 구현을 드러내고, 도메인의 핵심 개념이나 의도를 감춘다. 따라서 의미있는 이름으로 해당 Method의 이름을 짓자.(private으로 setter를 만드는 것은 나쁘지 않은 선택이다)
1장을 읽으면서 도메인 주도 개발이 최대한 현실세계를 반영한 코드를 작성하려는 노력이라는 것을 느낄 수 있었다. 이를 위해서 특히 노력해야 할 점이 바로 변수 이름 정하기이다. 변수의 이름을 정하기 위해서 많은 시간을 할애하는 것을 아까워 하지 말자. 각 단어의 미묘한 차이나 뉘앙스를 파악하기 어려워도 꼭 사전을 뒤져서라도 좋은 이름을 짓자. 이는 도메인 주도개발을 통해 이루고자 하는 도메인을 더 잘 이해하는 프로그램 만들기의 최악의 적이다.
높은 가용성 : 일부 서버에 장애가 발생하거나, 느려지거나, 네트워크 일부가 끊겨도 시스템은 계속 사용할 수 있어야 합니.
개략적 추정
- 가입 사용자는 오천만, DAU 1,000만
- 모든 사용자에게 10GB의 무료 저장공간 할당
- 매일 각 사용자가 평균 2개의 파일을 업로드한다고 가정합니다.
- 읽기:쓰기 = 1:1
- 필요한 저장공간 총량 = 5천만 * 10GB = 500페타바이트(Petabyte)
- 업로드 API QPS = 1천만 사용자 * 2회 업로드/24시간/3,600초 = 약 240
- 최대 QPS = QPS * 2 = 480
개략적 설계
우선 한 대의 서버로 시작해서 점진적으로 천만 사용자 지원이 가능한 시스템으로 만들어 보자. 한 대의 서버는 Web Server + DB + Storage(1TB)로 이루어질 것이다.
한 대 서버의 제약 극복
한 대의 서버의 1TB 공간을 모두 쓰면 데이터 샤딩을 통해 공간을 늘려준다.
서버의 장애로 데이터를 잃을 것을 걱정한다면 S3를 고려하자. S3를 통해 데이터 다중화를 할 때는 여러 지역에 걸쳐 bucket을 다중화하자. 이제 확장성, 가용성, 보안, 성능을 제공하는 객체 저장소 서비스인 S3를 활용하게 되었고, 데이터 손실 걱정이 줄었다. 하지만 저장소 외의 지점에서 발생하는 문제는 해결되지 않았다. 그래서 다른 부분을 고민해 본다.
- 로드 밸런서: 트래픽을 분산하고, 특정 웹서버에 장애가 발생하면 우회해 준다.
- 웹 서버: 로드 밸런서로 스케일 아웃이 쉬워진다. 즉 트래픽이 폭증해도 대응이 쉽다.
- 메타데이터 DB: DB를 파일 저장 서버에서 분리해서 SPOF를 피한다. 아울러 샤딩 및 다중화를 적용할 수 있다.
- 파일 저장소: S3를 사용하고, 가용성과 데이터 무손실을 위해 두 개 이상의 지역에 다중화한다.
동기화 충돌
두 명 이상의 사용자가 같은 파일이나 폴더를 동시에 업데이트 하면 충돌이 난다. 충돌을 해결하기 위해 먼저 처리되는 변경을 성공한 것으로 보고, 나중에 처리되는 변경은 충돌로 표시한다. 충돌이 발생하면 로컬 사본(local copy) 버전이 생성되고, 사용자는 두 파일을 합칠지, 하나를 선택할 지 결정해야 한다.
개략적 설계안(전체 설계안)
여기선 볼록 저장소 서버와 아카이빙 저장소, 그리고 오프라인 사용자 백업 큐만 언급한다.(나머지는 직관적이다)
- 블록 저장소 서버
파일을 블록 단위로 쪼개서 업로드 하는 서버다. 이 때 각 블록은 고유한 해시값이 할당된다. 그리고 이 해시값은 메타데이터 데이터베이스에 저장된다. 블록을 재구성하려면 블록들을 원래 순서대로 합쳐야 한다.
- 클라우드 저장소
블록 단위로 나눠져 클라우드 저장소에 보관된다.
- 아카이빙 저장소
오랫동안 사용되지 않은 비활성 데이터를 저장한다.
- 오프라인 사용자 백업 큐
클라이언트가 오프라인일 때 변경이나 알람을 큐에 두어 클라이언트가 접속 했을 때 동기화 한다.
상세 설계
상세 설계에선 블록 저장소 서버, 메타데이터 데이터베이스, 업로드 절차, 다운로드 절차, 알림 서비스, 파일 저장소 공간 및 장애 처리 흐름에 대해 더 자세히 알아본다.
블록 저장소 서버
파일 업데이트가 일어날 때마다 전체 파일을 갱신하면 네트워크 비용이 비싸다. 이를 위해 두 가지 해결책이 있다.
- 델타 동기화: 파일이 수정되면 변경된 블록만 갱신하는 방식
- 압축: 블록 단위로 압축해두면 데이터 크기를 줄일 수 있다.
높은 일관성 요구사항
이 시스템은 강한 일관성 모델을 기본으로 지원해야 한다. 이를 위해서 메모리 캐시가 일반적으로 지원하는 최종 일관성 모델에서 약간의 장치를 추가해야 하는데, 그건 원본에 변경이 발생하면 캐시를 무효화 하는 작업이다.
RDB는 강한 일관성을 보장하기 쉽지만, NoSQL은 그렇지 않으므로 동기화 로직 안에 프로그램해 넣어야 한다. 이 시스템은 RDB를 사용해서 일관성 요구사항에 대응한다.
메타데이터 데이터베이스
메타데이터 데이터베이스 스키마 설계안은 다음과 같다.
업로드 절차
파일 수정의 경우도 업로드와 비슷하므로, 따로 언급하지 않는다.
다운로드 절차
알림 서비스
알림 서비스는 롱 폴링, 웹소켓 방식 중에 선택해야 한다. 이 중 본 설계안 은 롱 폴링을 사용할 것이다. 그 이유는 채팅서비스와 달리 양방향 통신이 필요치 않고, 웹소켓은 알림을 보낼 일은 그렇게 자주 발생하지 않으며, 단시간에 많은 양의 데이터를 보내지 않는 구글 드라이브에 적합하지 않다.
저장소 공간 절약
파일 갱신 이력을 보존하고 안정성을 보장하기 위해서는 파일의 여러 버전을 저장해야 한다. 하지만 보드 백업하면 용량이 부족하니, 다음과 같은 전략을 사용하자.
- 중복 제거: 중복된 파일 블록은 제거하자
- 지능적 백업 전략: 한도 설정(파일 버전 갯수 제한), 중요 버전만 보관(자주 변경되는 문서는 불필요한 저장본 제거)
장애 처리
몇 가지 종류의 장애를 살펴보자
- 로드밸런서 장애: 로드 밸런서끼리 박동 신호를 통해 장애를 감지하자
- 블록 저장소 서버 장애: 다른 서버가 미완료 상태 또는 대기 상태인 작업을 이어받아야 한다.
- 클라우도 저장소 장애: 한 지역에서 장애가 발생하였다면 다른 지역에서 파일을 가져오자
- API 서버 장애: API서버는 로드 밸런서가 요청을 할당하지 않으므로 격리할 수 있다.
- 메타데이터 캐시 장애: 캐시 서버도 다중화한다.
- 메타데이터 DB장애: 주 DB 서버 장애는 부 DB서버를 주 DB서버로 만들고 부 DB서버 하나를 추가한다. 부 DB 서버 장애는 다른 부 DB서버에게 읽기 연산을 위임하고, 다른 서버 하나를 추가한다.
- 알림 서비스 장애: 한 서버에 장애가 발생하면 수만 명 이상의 사용자가 롱 폴링 연결을 새로 만들어야 함(복구 오래걸림)
사실 필자는 유튜브가 없으면 10배는 괜찮은 사람이었을 것이라고 확신한다. 유튜브는 너무 재밌고 자극적이며, 의도를 가지고 행동하는 것을 방해한다. 하지만 우린 엔지니어니 이런 사견은 접어두고 유튜브 설계를 공부해 보는 로 하자.
요구사항
- 비디오를 올리고 시청하는 기능을 구현한다.
- 모바일 앱, 웹 브라우저, 스마트 TV를 지원한다.
- DAU는 5백만이다.
- 평균적으로 30분 사용한다.
- 다국어 지원을 해야 한다.
- 현존하는 비디오 종류와 해상도를 대부분 지원한다
- 암호화가 필요하다.
- 비디오는 작거나 중간 크기에 중점을 두자. 최대 크기는 1GB이다.
- 클라우드 서비스를 사용할 수 있다.
이번 장에는 아래와 같은 기능에 초점을 맞춘다.
- 빠른 비디오 업로드
- 원활한 비디오 재생
- 재생 품질 선택 기능
- 낮은 인프라 비용
- 높은 가용성과 규모 확장성, 그리고 안정성
- 지원 클라이언트: 모바일 앱, 웹브라우저, 그리고 스마트 TV
개략적 규모 추정
- DAU : 5백만
- 1인당 하루 평균 5개의 비디오 시청
- 10%의 사용자가 하루에 1 비디오 업로드
- 비디오 평균 크기는 300MB
- 비디오 저장을 위해 매일 새로 요구되는 저장 용량 = 5백만 * 0.1 * 300MB = 150TB
- CDN 비용 $0.02 * 5백만 * 5 * 0.3GB = $150,000
개략적 설계안
이제 비디오 업로드 절차와 비디오 스트리밍 절차를 살펴보자.
비디오 업로드 절차
위의 그림에서 우리가 익숙하지 않은 트랜스코딩 서버만 살펴보자.
- 트랜스코딩 서버
비디오 트랜스코딩은 비디오 인코딩이라 부기도 하는 절차로, 비디오의 포맷을 변환하는 절차이다.
- 트랜스코딩 비디오 저장소
트랜스코딩이 완료된 비디오를 저장하는 BLOB 저장소다.
- 트랜스코딩 완료 큐
트랜스코딩이 완료되었다는 이벤트를 트랜스코딩 완료 핸들러에게 전달하기 위한 큐다.
- 트랜스코딩 완료 핸들러
메타데이터 캐시와 DB를 갱신하기 위한 작업 서버다.
비디오가 업로드 프로세스
1. 비디오 원본 저장소에 업로드 한다.
2. 트랜스코딩 서버는 원본 저장소에서 해당 비디오를 가져와 트랜스코딩을 시작한다.
3. 트랜스코딩이 완료되면 아래 두 절차가 병렬적으로 수행된다.
3a. 완료된 비디오를 트랜스코딩 비디오 저장소로 업로드한다.
3b. 트랜스코딩 완료 이벤트를 트랜스코딩 비디오 저장소로 업로드한다.
3a.1. 트랜스코딩이 끝난 비디오를 CDN에 올린다.
3b.1. 완료 핸들러가 이벤트 데이터를 큐에서 꺼낸다.
3b.1.a, 3b.1.b. 완료 핸들러가 메타데이터 데이터베이스와 캐시를 갱신한다.
4. API 서버가 달말에게 비디오 업로드가 끝나서 스트리밍 준비가 되었음을 알린다.
메타데이터 갱신 프로세스
원본 저장소에 파일이 업로드되는 동안, 단말은 비디오 메타데이터 갱신 요청을 API서버로 보낸다.
비디오 스트리밍 절차
유튜브에서 비디오 재생을 하면 비디오를 전부 다운받아야 재생이 되는 불편함은 없다. 이는 스트리밍 프로토콜을 활용했기 때문에 가능하다. 스트리밍 프로토콜은 다양한데, 각각은 지원하는 비디오 인코딩이 다르고 플레이어도 다르다.
비디오는 CDN에서 바로 스트리밍 된다. 이때 사용자의 단말에서 가장 가까운 CDN edge Server가 비디오 전송을 담당한다.
상세 설계
상세 설계에서는 최적화 방안과 함께 오류 처리 메커니즘에 대해 소개한다.
비디오 트랜스코딩
비디오를 생성하면 단말에 따라 특정 포맷으로 저장된다. 이 비디오는 다른 단말과의 호환성을 위해 특정 비트레이트(비디오를 구성하는 비트가 얼마나 빨리 처리되어야 하는지 나타내는 단위)로 저장되어야 한다. 그리고 이 과정을 비디오 트랜스코딩이라 부른다. 그리고 다음과 같은 이유로도 비디오 트랜스코딩은 중요하다.
- 원본 비디오는 저장 공간을 많이 차지한다.
- 상당수의 단말과 브랑우저는 특정 포맷만 지원한다. 따라서 하나의 비디오를 여러 포맷으로 인코딩 해둬야 한다.
- 사용자의 네트워크 상황에 따라 비디오의 화질을 구분해서 보내줘야 한다.
- 네트워크 상황이 수시로 변경되기 떄문에 비디오 화질을 자동으로 변경하거나 수동으로 변경할 수 있어야 한다.
유향 비순환 그래프(DAG) 모델
콘텐츠 제작자는 다양한 요구사항을 가지고 있다. 예컨데 워터마크를 표시하거나, 썸네일을 직접 만들거나, 화질을 다르게 할 수도 있을 것이다. 이처럼 각기 다른 비디 오프세싱 파이프라인을 지원하고, 처리 과정의 병렬성을 높이기 ㅎ위해서 유향 비순한 그래프(DAG) 프로그래밍 모델을 도입할 필요가 있다.
비디오 트랜스코딩 아키텍쳐
DAG를 활용한 실제 설계안은 다음과 같다.
- 전처리기
전처리기는 비디오를 분할하고, DAG를 생성한다.(적절한 작업을 조립하는 과정이다) 그리고 분할된 비디오 데이터를 캐시한다.
- DAG 스케줄러
스케줄러는 DAG 그래프를 몇 단계로 분할한 후 각각을 자원 관리자의 작업 큐에 집어넣는다. 아래의 그림에선 DG를 2개 작업 단계로 쪼갠 사례다. 여기서 실제 작업이 이루어 지는 것은 아니고 단지 DAG를 정의해주는 과정이라 이해하면 좋다.
- 자원 관리자
자원 관리자는 자원 배분을 효과적으로 수행하는 역할을 담당한다. 자원 관리자는 작업 큐(우선순위 큐)에서 작업을 꺼내서 작업 서버를 고른 후에 해당 작업 서버에게 작업 실행을 지시하고, 해당 작업이 어떤 서버에 할당되었는지에 관한 정보를 실행 큐에 넣는다. 그리고 작업 완료 시점에 해당 작업을 실행큐에서 제거한다.
- 작업 서버
DAG에서 정의된 작업을 수행한다.
- 임시 저장소
비디오 프로세싱이 진행되는 동안 캐시로 사용된다. 여기엔 비디오/오디오, 메타데이터 등일 담길 수 있다.
시스템 최적화
속도, 안정성, 비용 측면에서 이 시스템을 최적화 해보자.
속도 최적화
비디오를 GOP들로 분할해서 병렬적으로 업로드 하면 일부가 실패해도 빠르게 업로드를 재개할 수 있다.
업로드 센터를 사용자 근거리에 지정하면 속도의 최적화를 달성할 수 있다.
마지막으로 모든 절차를 느슨하게 결합되도록 해서 병렬성을 높이는 것이 가능하다. 이를 위해서 각 컴포넌트의 통신을 메시지 큐로 결합도를 낮추자.
안정성 최적화
허가받은 사용자만 비디오를 업로드 하기 위해 인증된 URL을 이용하자.
비디오의 저작권 보호를 위해 다음 3가지 선택지 중 하나를 선택할 수 있다.
- 디지털 저작권 관리 시스템 도입: 애플의 페어플레이, 구글의 와이드바인, MS의 플레이레디가 있다.
- AES 암호화: 비디오를 암호화하고 접근 권한을 설정하는 방식
- 워터마크: 비디오 위에 소유자 정보를 포함하는 이미지 오버레이를 올리는 방식
비용 최적화
- 인기 비디오는 CDN에서, 다른 비디오는 비디오 서버를 통해 재생하기
- 인기 없는, 또는 짧은 비디오는 필요할 때 인코딩 해서 재생
- 특정 지역에서만 인기있는 비디오는 다른 지역에 옮기지 않기
- CDN을 직접 구축하고 ISP와 제휴
오류처리
시스템 오류는 두 가지 종류가 있다.
- 회복 가능 오류: 특정 세그먼트를 트랜스코딩하다 실패 하는 등의 문제는 재시도. 하지만 반복되면 오류코드를 반환.
- 회복 불가능 오류: 포맷이 잘못되는 등의 오류는 작업을 중단하고 클라이언트에게 오류코드를 반환.
- 데이터 수집 서비스 : 사용자가 입력한 질의를 실시간으로 수집하는 시스템(실시간은 부적절 하지만 차후 보안하자)
- 질의 서비스 : 주어진 질의에 다섯 개의 인기 검색어를 정렬해 내놓는 서비스
데이터 수집 서비스
데이터 수집 서비스는 각각의 검색어가 몇번의 질의를 받았는지 기록해 두는 시스템이다. 만약 사용자가 twitch, twitter, twitter, twillo를 순서대로 검색하면, 다음과 같이 테이블에 데이터가 변경되어간다.
1. twitch : 1
2. twitch : 1
twitter : 1
3. twitch : 1
twitter : 2
4. twitch : 1
twitter : 2
twillo : 1
질의 서비스
앞서 기록한 데이터 수집 서비스에서 저장한 데이터에 SQL Query를 사용해 가장 많이 사용된 5개의 검색어를 계산할 수 있다.
SELECT * FROM frequency_table
WHERE query Like `prefile%`
ORDER BY frequency DESC
LIMIT 5;
데이터 양이 적다면 나쁘지 않은 설계안이다. 하지만 데이터가 많아지면 데이터베이스가 병목이 될 수 있다. 이제 이 문제를 해결할 방법을 앞으로 알아본다.
상세 설계
앞선 개략적 설계안을 개선하기 위해 트라이 자료구조, 데이터 수집 서비스, 질의 서비스 순으로 살펴보자.
트라이 자료구조
트라이 자료구조에 대한 상세한 설명은 이미 잘 알려져 있고, 좋은 자료도 많기 때문에 생략하겠다. 하지만 트라이 자료구조의 한계를 잠깐 언급하고 이어서 한계를 극복하는 방식에 대해 이야기 하겠다.
트라이 자료구조는 탐색을 위해 O(p) + O(c) + O(clogc) 이다. 이때 p는 접두어의 길이, n은 트라이 안에 있는 노드 개수, c는 주어진 노드의 자식 노드 개수이다. 이 알고리즘은 직관적이지만 최악의 경우에는 k개의 결과를 얻으려고 전체 트라이를 다 검색해야 하는 일이 생길 수 있다. 이 문제를 해결하기 위해 접두어 최대 길이 제한, 노드에 인기 검색어 캐시 하는 방식으로 최적화를 진행한다.
- 접두어 최대 길이 제한
앞서 접두어의 길이 p는 시간 복잡도에 영향을 끼친다. 여기서 접두어의 길이를 상수, 예컨데 50으로 제한 한다면 O(p)는 O(1)으로 변경된다.
- 노드에 인기 검색어 캐시
각 노드에서 인기있는 검색어 5개를 저장해 두면 시간 복잡도를 엄청나게 낮출 수 있다. 물론 저장 공간을 많이 희생하게 된다는 단점이 있지만, 빠른 응답속도가 아주 중요할 때는 희생할 만한 가치가 있다.
앞선 두가지의 최적화를 진행하면 접두어 노드를 찾는 시간 복잡도는 O(1)이 되고, 최고 인기 검색어 5개를 찾는 질의의 시간 복잡도도 O(1)이 된다. 즉, 전체 알고리즘의 복잡도도 O(1)이 된다.
데이터 수집 서비스
최초의 설계안은 요청이 들어올 때 마다 실시간을 데이터를 수정했다. 하지만 이 방식은 매일 수천만 건의 질의가 입력되는 요구사항에서는 심각하게 느려질 것이다. 또한 트라이가 만들어지고 나면 인기 검색어는 자주 변경되지 않기 때문에 비효율 적이다.
이 문제들을 해결하기 위해 개선된 설계안은 다음과 같다. 아래에서 개선된 설계안의 각 컴포넌트에 대한 설명을 이어서 한다.
- 데이터 분석 서비스 로그
데이터 분석 서비스 로그에는 사용자가 입력한 질의를 저장한다. 수정이나 삭제는 이루어지지 않으며, 로그 데이터에는 인덱스를 걸지 않는다.
Query
Time
tree
2023-01-01 22:01:02
try
2023-01-01 22:01:03
test
2023-01-01 22:01:06
- 로그 취합 서버
데이터 분석 서비스에서 적재된 로그는 일정한 주기로 검색 횟수를 취합한다. 이때 트위터와 같이 데이터의 신선도가 중요한 서비스는 자주 취합해 주고, 구글과 같은 서비스는 더 긴 주기를 가져도 좋을 것이다.
- 취합된 데이터
time 필드는 해당 주가 시작된 날짜를 나타낸다.
query
time
frequency
tree
2023-01-01
12000
tree
2023-01-08
15000
tree
2023-01-15
9000
toy
2023-01-01
8500
toy
2023-01-08
6256
toy
2023-01-15
8866
- 작업 서버
작업 서버는 주기적으로 비동기적 잡업(job)을 실행하는 서버 집합이다. 트라이 자료구조를 만들고 트라이 데이터베이스에 저장하는 역할을 담당한다.
- 트라이 캐시
트라이 캐시는 분산 캐시 시스템으로 트라이 데이터를 메모리에 유지하여 읽기 연산 성능을 높인다.
- 트라이 데이터베이스
Document Store와 Key-Value Store를 통해 지속성 저장소를 구현할 수 있는데, 이 책에선 키-값 저장소를 사용한다.
질의 서비스
개략적 설계안에서는 DB를 활용하여 인기 검색어 5개를 골라냈다. 개선된 설계안은 기존 설계안의 비효율성을 개선한 설계안이다.
트라이 연산
트라이는 자동완성 시스템의 핵심 컴포넌트이다. 이제 트라이 관련 연산들이 어떻게 이루어 지는지 보자.
- 트라이 생성
트라이 생성은 작업 서버가 담당하며, 취합된 데이터를 활용한다.
- 트라이 갱신
트라이 갱신은 매주 새로운 트라이를 만든 후에 대체하는 방법과 각각의 노드를 개별적으로 갱신하는 방법이 있다. 작가는 매주 새로운 트라이를 만드는 방법을 사용했는데, 이는 성능이 좋지 않기 때문이다.
- 검색어 삭제
몇몇 단어는 혐오성이 짙거나, 폭력적이거나, 성적으로 노골적인 듯 문제가 되는 검색어를 자동완성 결과에서 제거해야 한다. 이를 위해 캐시 앞에 필터 계층을 두고 부적절한 질의어가 반환되지 않도록 하는 것을 추가할 수 있다.
저장소 규모 확장
영어만 지원하지 때문에 첫 글자를 기준으로 샤딩할 수 있다. 영어는 26글자니까 추가로 샤딩하기 위해서 두 번째 글자까지 샤딩할 수 있다. 하지만 모든 글자가 해당 글자로 시작되는 단어를 동일하게 가지고 있는 것은 아니다. 이를 위해서 과거 질의 데이터의 패턴을 분석해서 샤잉하는 방법을 사용한다.