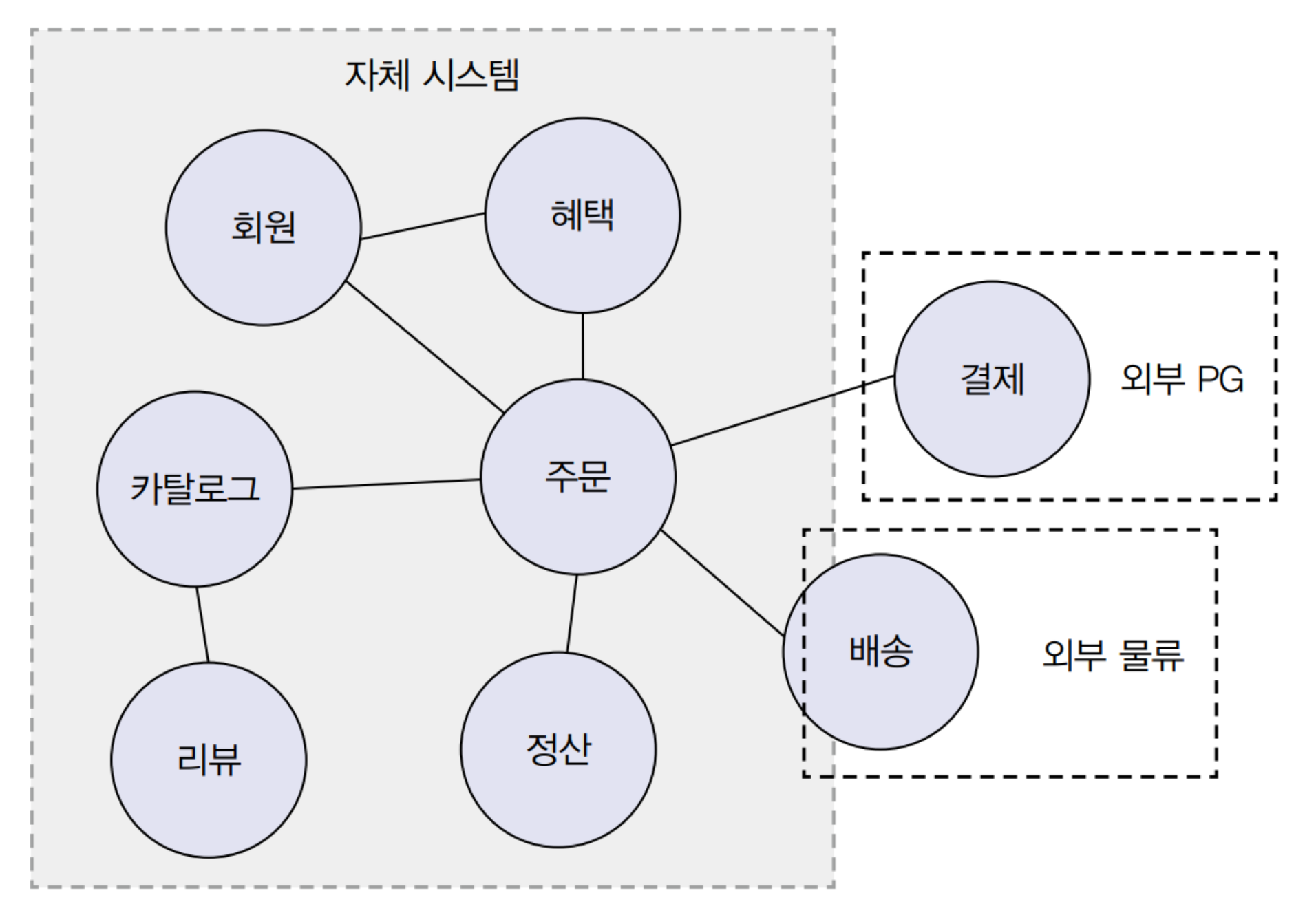
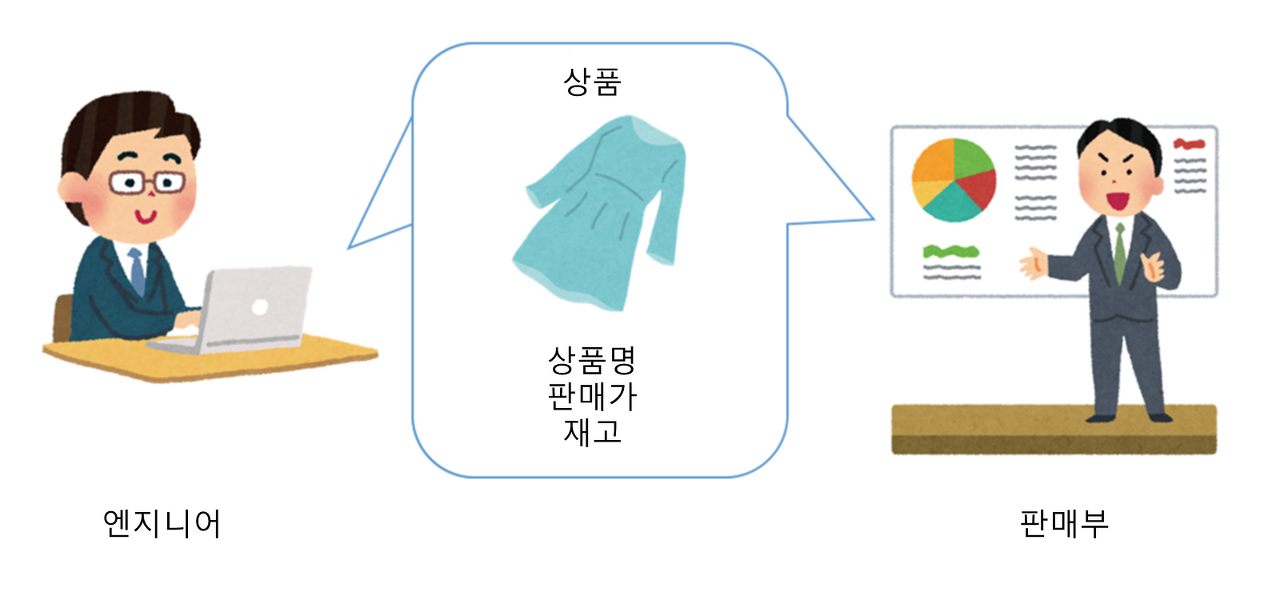
온라인 서점을 구현한다고 해보자. 그럼 우리는 어떤 책이 나왔는지 검색하고, 목차와 서평을 보기도 한다. 그리고 주문하고 결제하고 배송하며, 리뷰를 하기도 한다. 이렇게 우리가 소프트웨어로 해결하고자 하는 모든 영역을 도메인이라고 한다.
앞서 말한 다양한 기능은 하위 도메인으로 볼 수 있다.
하지만 이 중에 배송과 결제 같은 기능은 개발자가 직접 해결하지 않기도 한다.
도메인 모델
도메인 모델 : 특정 도메인을 개념적으로 표현한 것
도메인 모델을 사용해서 여러 관계자들이 동일한 모습으로 도메인을 이해하고 도메인 지식을 공유하는 데 도움이 된다.
도메인 모델링은 다양한 방법을 활용할 수 있다.
주문 도메인을 모델링 해보자.
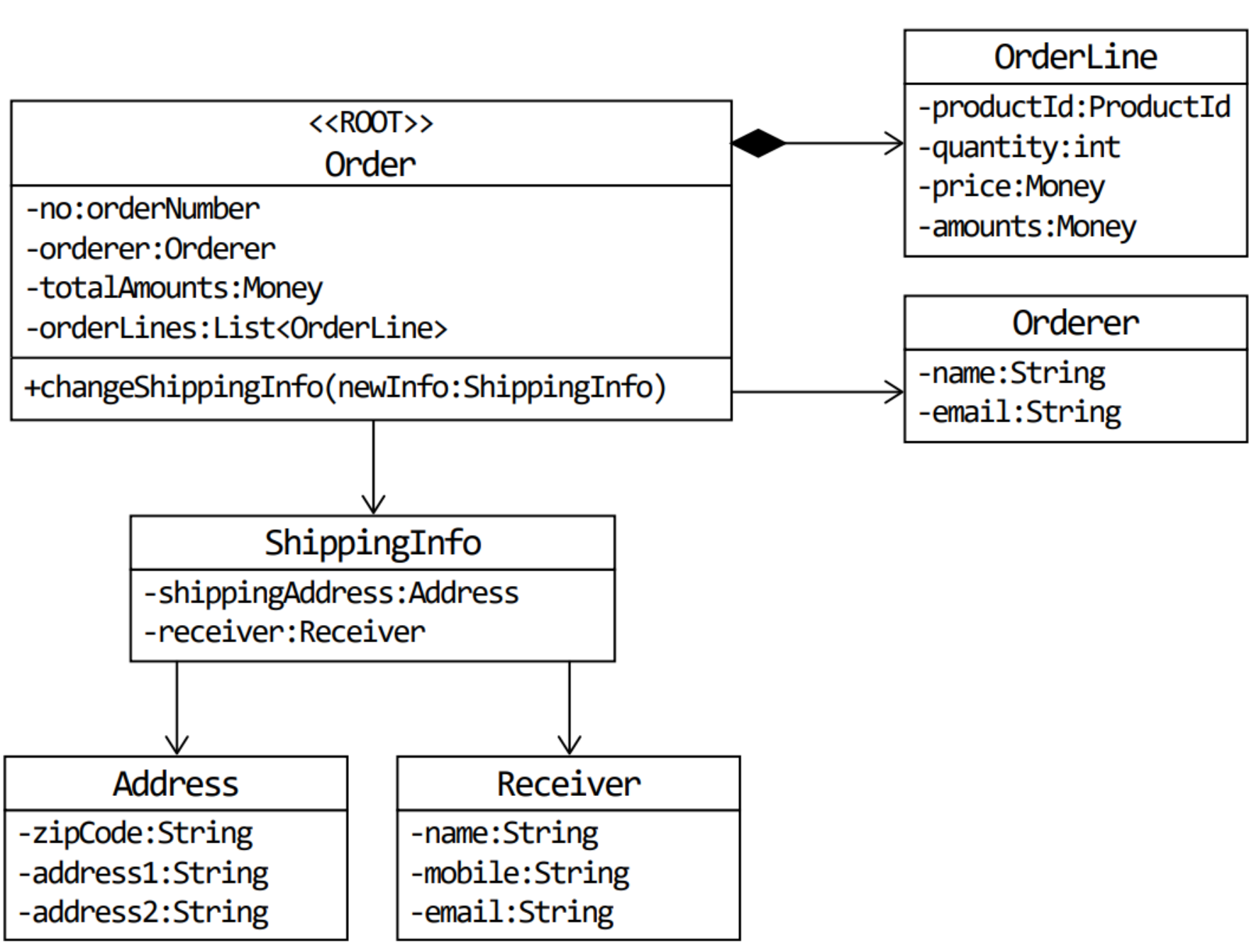
이제 이 그림을 통해 도메인을 이해할 수 있다. 이 모델을 통해 주문은 주문 번호, 지불 금액 등을 가지고 있고, 배송 정보를 변경하거나 주문을 취소할 수 있다는 사실을 알 수 있다.
위의 그림은 객체를 이용한 도메인 모델이다. 객체 모델링은 기능과 데이터를 함께 보여줘서 편리하지만, 다른 방법을 활용할 수도 있다.
이 그림은 상태 다이어그램으로 표현한 도메인 모델이다. 이 다이어그램을 통해 상품 준비 중 상태에서 주문을 취소하면 결제 취소가 함께 이루어진다는 것을 알 수 있다.
상황에 따라서는 그래프를 이용할 수도 있고, 수학 공식을 이용할 수도 있다. 중요한 것은 도메인을 이해하는데 도움만 되면 된다는 것이다.
도메인 모델 패턴
영역
설명
사용자 인터페이스 또는 표현
요청을 처리하고 사용자에게 정보를 보여준다. 여기서 사용자는 소프트웨어를 사용하는 사람 뿐만 아니라 외부 시스템일 수도 있다.
응용
사용자가 요청한 기능을 실행한다. 업무 로직을 직접 구현하지 않으며 도메인 계층을 조합해서 기능을 실행한다.
도메인
제공할 도메인 규칙을 구현한다.
인프라스트럭처
메시징 시스템과 같은 외부 시스템과의 연동을 처리한다.
전체적인 아키텍처와 각 영역은 뒤에서 자세히 설명한다.
도메인 모델 도출
개발의 시작은 도메인에 대한 이해이다. 기획서, 유스케이스, 사용자 스토리와 같은 요구사항을 통해 도메인 모델 초안을 만들어야 비로소 코드를 작성할 수 있다.
예컨데, 주문 요구사항을 모델링 하면 다음과 같다.
엔티티와 벨류
앞선 요구사항 분석 과정에서 만든 모델은 다음과 같다.
도출한 엔티티 모델의 각 요소는 엔티티와 벨류로 구분할 수 있다.
엔티티
식별자를 가진다.
내용이 바뀌어도 식별자가 변하지 않는다.
벨류타입
개념적으로 완전한 하나를 표현할 때 사용한다.
벨류타입을 위한 기능을 추가할 수 있다.
불변으로 구현해야 한다.(Setter 금지!)
개념적으로 완전히 하나를 표현
벨류 타입을 위한 기능
아키텍처 개요
DDD 아키텍처
응용 영역이나 도메인 영역은 인프라 기능을 사용하므로 인프라 계층에 종속된다. 이는 2가지 문제를 가져온다.
인프라가 구현되기 전까지 테스트가 어렵다.
구현 방식을 변경하기 어렵다.
코드만 보면 DI로 해결할 수 있을 것 같지만, 간접적인 의존이 존재한다.
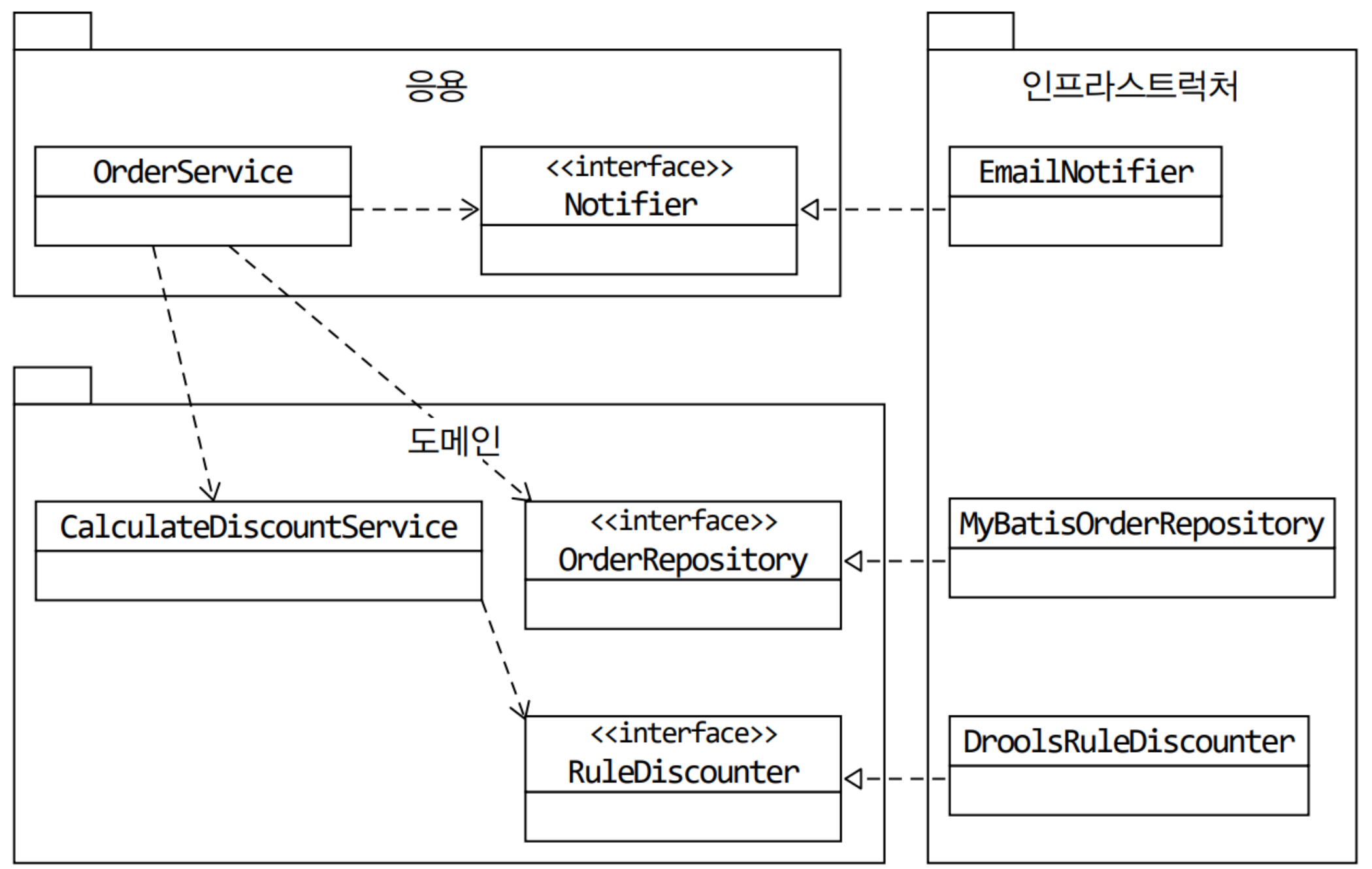
DIP
DIP = 의존 관계 역전 원칙 = 저수준 모듈이 고수준 모듈에 의존하도록 바꾼다.
주의 사항
단순히 DroolsRuleDiscounter에서 인터페이스를 분리한다고 생각하면 안된다. 인터페이스는 고수준 모듈 입장에서 도출해야 한다. 따라서 인터페이스는 저수준 모듈이 아닌 고수준 모듈에 위치한다.
도메인 영역의 주요 구성요소
애그리거트
도메인이 커질수록 도메인 모델은 복잡해지고 엔티티와 벨류 개수가 많아진다. 이때 도움이 되는 개념이 애그리거트이다. 애그리거트는 관련 객체를 하나로 묶은 군집이다.
예컨데 온라인 서점 서비스에서 주문은 하나의 애그리거트가 된다. 이때 애그리 거트는 군집에 속한 객체를 관리하는 루트 엔티티를 갖는다. 루트 엔티티는 애그리거트에 애그리거트가 구현해야 할 기능을 제공한다.(애그리거트 단위로 구현을 캡슐화한다.)
모듈 구조
애그리거트
도메인 모델이 복잡해지면 관계를 파악하기 어렵고 확장이 어려워진다. 이를 해결하기 위해 거대한 도메인 모델을 작은 애그리거트 단위로 나눈다.
애그리거트에 속한 객체는 유사하거나 동일한 라이프 사이클을 가진다.
애그리거트는 경계를 갖는다.
한 애그리거트에 속한 객체는 다른 애그리거트에 속하지 않는다
애그리거트는 자기 자신만 관리할 뿐, 다른 애그리거트를 관리하지 않는다.
경계는 도메인 규칙과 요구사항으로 결정된다.(생명 주기를 살펴보자.)
흔히 ‘A가 B를 갖는다’로 설계할 수 있는 요구사항이 있다면 A와 B를 한 애그리거트로 묶어서 생각하기 쉽다. 주문의 경우 Order가 ShippingInfo와 Orderer를 가지므로 이는 어느 정도 타당해 보인다. 하지만 ‘A가 B를 갖는다’로 해석할 수 있는 요구사항이 있다고 하더라도 이것이 반드시 A와 B가 한 애그리거트에 속한다는 것을 의미하는 것은 아니다.
좋은 예가 상품과 리뷰다. 상품 상세 페이지에 들어가면 상품 상세 정보와 함께 리뷰 내용을 보여줘야 한다는 요구사항이 있을 때 Product 엔티티와 Review 엔티티가 한 애그리거트에 속한다고 생각할 수 있다. 하지만 Product와 Review는 함께 생성되지 않고, 함께 변경되지도 않는다. 게다가 Product를 변경하는 주체가 상품 담당자라면 Review를 생성하고 변경하는 주체는 고객이다.
애그리거트 루트
애그리거트는 개념적으로 하나이기 때문에 모든 객체가 일관된 상태를 유지해야 한다. 예컨데, 주문 애그리거트에서 상품 가격이 변경되면 총 금액도 변경되어야 하는 것이다. 이러한 애그리거트에 속한 모든 객체의 일관성을 유지하는 책임을 지는 것이 애그리거트 루트이다.
이 목표를 달성하기 위한 3가지 원칙이 있다.
애그리거트의 모든 기능은 애그리거트 루트를 통해 실행한다.
단순히 필드를 변경하는 set 메서드는 public으로 만들지 않는다.
밸류 타입은 불변으로 구현한다.
애그리거트의 트렌젝션
트렌젝션은 작을수록 좋다. 한 트렌젝션이 여러 테이블을 변경하면 성능이 떨어지기 때문이다. 동일하게 한 트렌젝션에서는 한 개의 애그리거트만 수정해야 한다.
만약 부득이하게 한 트렌젝션에서 두 애그리거트를 수정해야 한다면 다음과 같은 방법을 고려할 수 있다.
Application 계층에서 애그리거트를 사용하는 트렌젝션을 구현
도메인 이벤프를 사용해서 동기 또는 비동기로 다른 애그리거트의 상태를 변경
다른 애그리거트를 사용하는 트렌젝션의 예시
리포지터리와 애그리거트
애그리거트는 개념상 완전한 한 개의 도메인 모델을 표현하므로 영속성을 처리하는 리포지터리는 애그리거트 단위로 하나만 존재한다. 따라서 리포지터리는 완전한 애그리거트를 제공해야 하고, 저장시 애그리거트 전체를 영속화 해야 한다.
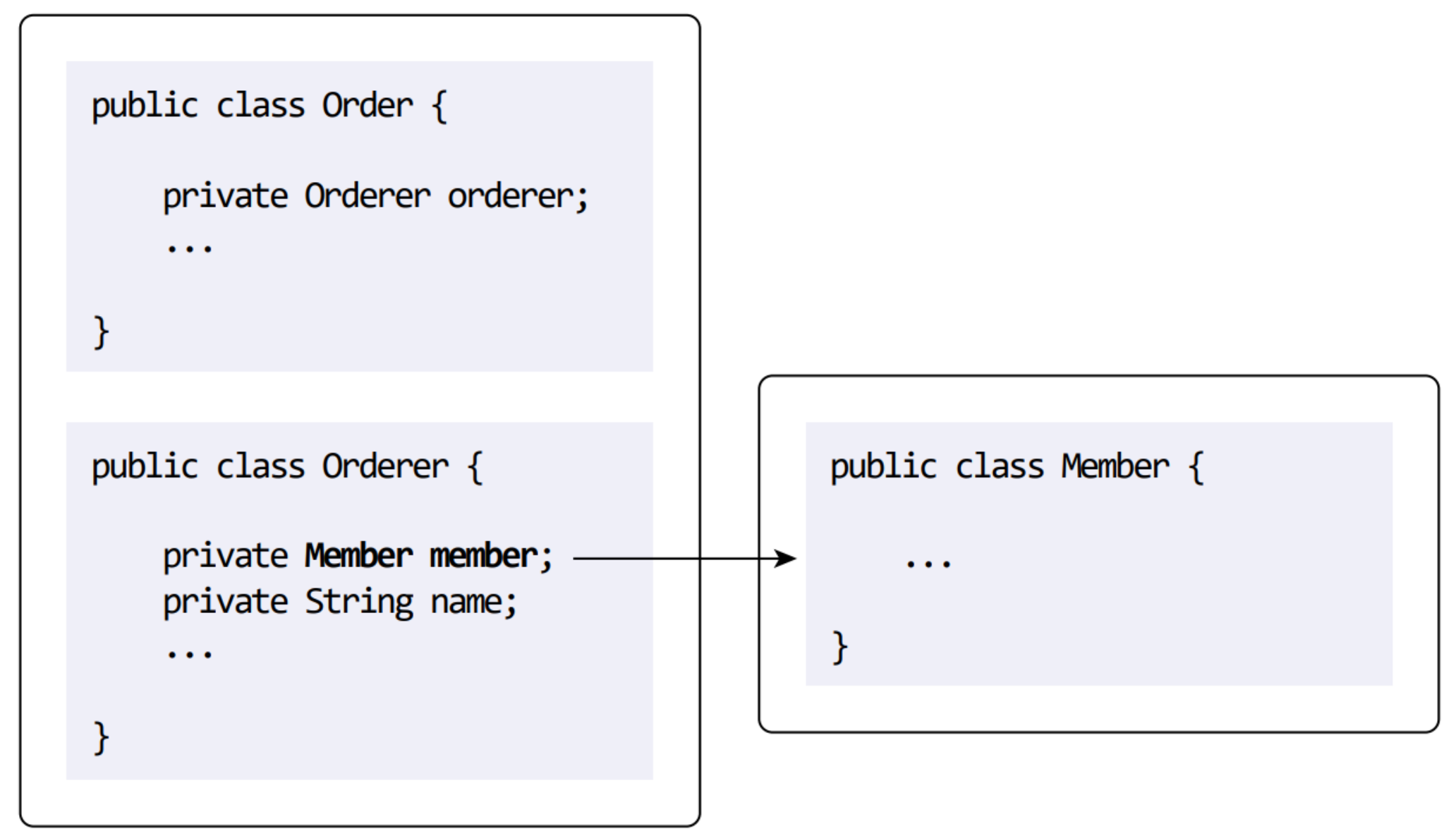
ID를 이용한 애그리거트 참조
한 애그리거트가 다른 애그리거트를 참조하기도 한다. 가장 쉬운 방법은 회원 애그리거트 루트인 Member를 참조할 수 있다.
하지만 이 방식은 다음과 같은 문제를 가지고 있다.
편한 탐색 오용 - 다른 애그리거트 상태를 쉽게 변경할 수 있음.
성능에 대한 고민 - 지연/즉시 로딩 방법 고민
확장 어려움 - 다른 애그리거트가 같은 DBMS를 사용하지 않게 된다면?
따라서 다른 애그리거트의 루트를 참조하는 것이 아니라, ID만 가지고 있는 방식으로 애그리거트 참조를 구현한다.
성능 문제가 발생하지 않을까요?
다른 애그리거트를 ID로 참조하면 N+1 문제가 발생한다. 그렇다고 JOIN 사용하면 ID참조 방식에서 객체 참조 방식으로 되돌리는 꼴이다. 이를 해결하기 위해 조회 전용 쿼리를 사용하는 것이 좋다.
이후에 CQRS 패턴에서 더 자세히 알아본다.
응용 서비스와 표현 영역
표현 영역은 사용자의 요청을 해석한다.
응용 영역은 사용자가 원하는 기능을 제공한다.
응용 서비스의 역할
응용 서비스는 사용자가 요청한 기능을 실행한다. 이를 위해 리포지터리에서 도메인 객체를 가져와 사용한다.
응용 서비스의 역할
도메인 객체 간의 흐름을 제어한다. (facade pattern을 생각하면 편하다)
트랜잭션 처리를 담당한다.
기능의 인가 확인
응용 서비스의 주의사항
도메인 로직 넣지 않기
응용 서비스의 고민거리
응용 서비스의 크기
회원 도메인을 생각하면, 회원 가입 탈퇴 암호 변경 비밀번호 초기화와 같은 기능을 한 응용 서비스에 다 넣을지 기능 별로 응용 서비스를 만들지 고민하게 된다.
한 클래스에 넣으면 코드 중복을 줄이게 된다. 하지만 응집도가 낮아진다.
응용 서비스에 인터페이스가 필요한가?
인터페이스는 테스트의 용이성과 확장의 용이성을 얻을 수 있다. 하지만 응용 서비스는 변경이 잦지 않고, Mockito와 같은 프레임워크로 테스트 용이성을 얻을 수 있다. 따라서 인터페이스는 전체 구조를 복잡하게 하는 나쁜 선택일 가능성이 높다.
표현 영역
표현 영역의 책임은 크게 다음과 같다.
사용자가 시스템을 사용할 수 있는 흐름(화면)을 제공하고 제어한다.
사용자의 요청을 알맞은 응용 서비스에 전달하고 결과를 사용자에게 제공한다.
사용자의 세션을 관리한다.
값 검증
값 검증은 표현 영역과 응용 서비스 두 곳에서 수행할 수 있다.
원칙적으로 모든 값에 대한 검증은 응용 서비스에서 처리한다. 하지만 Spring 프레임워크의 기능을 편리하게 사용하기 위해서 표현 영역에서도 값 검증을 수행하는 것이다(이는 Spring의 ModelAndView에 BindingResult를 활용하거나, Validator 기능을 활용하기 위함이다).
프레임워크를 활용하면 다음과 같이 역할을 나누어 검증을 수행할 수 있다.
표현 영역: 필수 값, 값의 형식, 범위 등 검증
응용 서비스: 데이터의 존재 유무와 같은 논리적 오류 검증
저자(최범균)은 최근에는 응용 서비스에서 필수 값 검증과 논리적인 검증을 모두 한다고 한다. 이는 응용 서비스의 완성도가 높아지는 이점이 있다고 한다.
권한 검사
권한 검사는 보통 3가지 영역에서 수행할 수 있다.
표현 영역
인증된 사용자인지 검증한다.
필터를 활용한다.
응용 서비스
URL만으로 접근 제어를 할 수 없는 경우 메서드 단위로 검사를 수행한다.
AOP를 활용한다.
도메인
게시글 삭제는 본인 또는 관리자만 할 수 있는 경우에는 도메인에서 권한 검사를 구현해야한다.
도메인 서비스
여러 애그리거트가 필요한 기능
특정 기능은 여러 애그리거트가 필요하다. 대표적인 예가 결제 금액 계산 로직이다.
상품 애그리거트: 구매하는 상품의 가격이 필요하다. 또한 배송비가 추가되기도 한다.
주문 애그리거트: 상품별로 구매 개수가 필요하다
할인 쿠폰 애그리거트: 쿠폰별로 할인을 받는다. 이때 카테고리별로 제약이 있다면 더 복잡해진다.
회원 애그리거트: 회원 등급에 따라 추가 할인이 가능하다.
이 내용을 한 애그리거트에 포함 시키면 책임을 넘는 기능을 구현하고, 외부 의존이 높아지며, 코드가 복잡해진다. 또한 애그리거트의 범위를 넘는 도메인 개념이 애그리거트에 숨어든다.
도메인 서비스
도메인 서비스는 상태를 가지지 않는다
구현에 필요한 상태는 다른 방법으로 전달 받는다(Param)
도메인 서비스를 사용하는 주체는 애그리거트가 될 수도 있고 응용 서비스가 될 수도 있다.
애그리거트 객체에 도메인 서비스를 전달하는 것은 응용 서비스 책임이다.
외부 시스템 연동과 도메인 서비스
외부 시스템이나 타 도메인과의 연동 기능도 도메인 서비스가 될 수 있다. 이는 도메인 관점에서 작성된 Interface와 실제 구현 부인 Infra가 포함된다.
설문 조사 도메인에서 설문 조사 생성 권한을 확인해야 할 수 있다. 이때 확인은 Member도메인과 연동이 필요하다.
이렇게 만든 도메인 서비스는 도메인 계층에 위치한다.
도메인 모델과 바운디드 컨텍스트
DDD는 모든 사람(소프트웨어 개발자, 도메인 전문가)이 동일한 의미로 말을 사용하는 것을 목적으로 한다. 하지만 도메인 모델에서는 개념적으로는 같은 것이 맥락에 따라 달라지는 경우가 있다. 아래의 그림을 보자.
개념적으로 같은 것이 맥락에 따라 달라지는 경우
이렇듯 시스템이 클수록, 관계자들은 통일된 하나의 모델을 만드는 것이 어려워 진다. 따라서 DDD에서는 바운디드 컨택스트를 정의한다.
바운디드 컨텍스트를 통해 의미를 명확하게 하기
바운디드 컨텍스트는 구현상으로 하나의 프로젝트 또는 어플리케이션으로 취급한다. 앞서 시스템의 크기를 작게 유지하기 위한 전략이다.
*모든 바운디드 컨텍스트가 DDD로 구현될 필요는 없다.
바운디드 컨텍스트는 모델의 경계를 결정하며 한 개의 바운디드 컨텍스트는 논리적으로 한 개의 모델을 갖는다.
이상적으로는 하위 도메인과 바운디드 컨텍스트가 1:1 관계를 가지면 좋겠지만, 현실은 기업의 팀 조직 구조로 인해 나눠지기도 하고 용어를 명확하게 구분하지 못해 두 하위 도메인을 하나의 바운디드 컨텍스트에서 구현하기도 한다.
바운디드 컨텍스트 간 통합
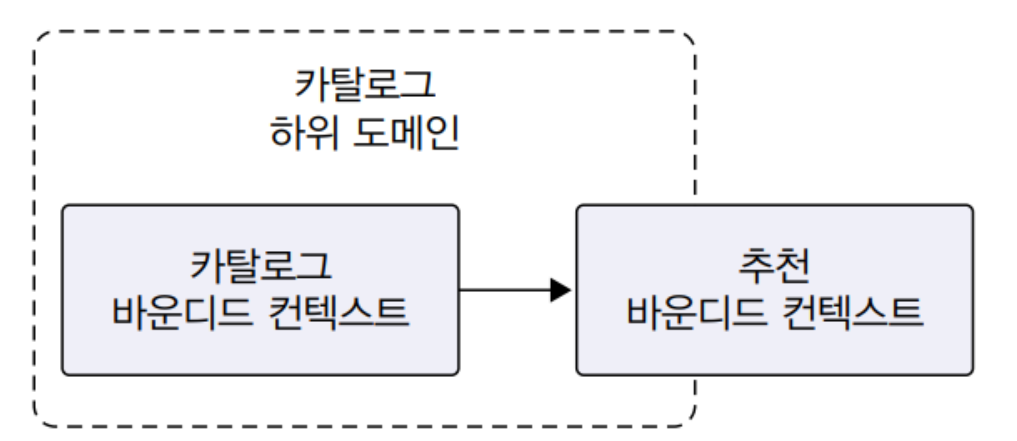
온라인 쇼핑 사이트에서 추천 시스템을 추가한다고 가정하자. 그리고 이를 위해서 새로운 팀이 꾸려졌다. 그럼 다음과 같이 바운디드 컨텍스트가 생긴다.
이제 두 바운디드 컨텍스트를 개발하기 위해 자연스럽게 바운디드 컨텍스트간 통합이 발생한다.
사용자가 제품 상세페이지를 볼 때, 보고 있는 상품과 유사한 상품 목록을 하단에 보여준다는 기능을 고민해보자. 이를 위해서 가장 먼저 생각할 수 있는 방법은 REST API를 사용하는 방법이다. 이는 두 바운디드 컨텍스트를 직접 통합하는 방식이다.
두 바운디드 컨텍스트를 간접적으로 통합하는 방법도 있다. 바로 메시지 큐를 사용하는 것이다.
그럼 비동기로 메시지를 처리하기 때문에 카탈로그 바운디드 컨텍스트는 메시지를 큐에 추가한 뒤 응답을 기다리지 않고 다른 작업을 마무리할 수 있다.
메시징 시스템을 사용하려면 데이터 형식을 맞춰야 한다. 이때 카탈로그 입장에서 데이터 구조를 만들지, 추천 입장에서 데이터 구조를 만들지 결정해야 한다.
카탈로그 도메인 관점 VS 추천 도메인 관점
이때 추천 도메인 관점에서 데이터 구조를 짜면 REST API를 사용해서 데이터를 전달하는 것과 차이가 없다.
컨텍스트 맵
개별 바운디드 컨텍스트에 매몰되면 전체를 보지 못할 때가 있다. 이를 방지하기 위해 컨텍스트 맵을 만들기도 한다. 이때 바운디드 컨텍스트의 주요 애그리거트를 함께 명시하면 더 좋다.
*OHS(오픈 호스트 서비스): 상류 팀의 고객인 하류 팀이 다수 존재할 때 상류 팀에서 하류 팀의 요구사항을 수용할 수 있는 API를 만들고 이를 서비스 형태로 공개하여 일관성을 유지할 수 있게 하는 서비스
*ACL(안티럽션 계층): 모델 변환을 처리
이벤트
이벤트가 필요한 상황을 위해 몇 가지 가정을 해보자.
쇼핑몰 주문 취소
외부 시스템(PG사)를 통해 환불을 진행해야 한다.
환불이 진행되면 이메일을 발송해야 한다.
API로 찔렀을 경우 문제점
외부 시스템이 불안정하여 응답이 늦을 수 있다.
PG사의 장애가 우리의 장애로 이어질 수 있다.
외부 시스템이 실패해도 주문 취소는 정상적으로 작동해야 한다.(나중에 환불을 재시도 한다.)
주문 취소와 환불은 서로 다른 트렌젝션으로 실행되어야 한다.
주문 도메인의 로직에 결제 로직(API 호출로직)이 섞일 수 있다. 또한 이메일 발송 로직도 마찬가지이다.
이 모든 문제는 시스템 사이의 강 결합 때문이다. 이를 해결하는 방법이 바로 이벤트다.
이벤트 개요
이벤트란 과거에 벌어진 어떤 것을 의미한다. 그리고 이 이벤트의 발행을 기준으로 다른 작업들을 수행할 수 있다. (JS의 이벤트를 생각하면 편하다)
이벤트는 크게 2가지 용도로 사용된다.
트리거
도메인의 상태가 변경되면 후 처리를 수행한다.
SMS 발송 등이 있다.
서로 다른 시스템 간의 데이터 동기화
주문 도메인에서 배송지를 변경하면 외부 배송 서비스와 배송지 정보를 동기화할 수 있다.
비동기 이벤트 처리
회원 가입 검증 이메일은 즉시 발송될 필요 없다. 10초 후여도 괜찮다. 심지어 이메일을 받지 못하면 재전송 할 수도 있다. 이를 위해 비동기 이벤트 처리를 사용할 수 있다.
이벤트를 비동기로 구현하는 방법은 다양한데, 그 중 네 가지 방식을 살펴보자
로컬 핸들러를 비동기로 실행하기
메시지 큐를 사용하기
이벤트 저장소와 이벤트 포워더 사용하기
이벤트 저장소와 이벤트 제공 API 사용하기
로컬 핸들러 비동기 실행
이벤트 핸들러를 별도 스레드로 실행하는 방법이다. Spring에서는 간단하게 @Async만 붙이면 된다.
메시징 시스템을 이용한 비동기 구현
Kafka나 RebbitMQ를 활용하는 방법이다.
필요하다면 이벤트를 발생시키는 도메인 기능과 메시지 큐에 이벤트를 저장하는 절차를 한 트랜잭션으로 묶어야 한다. 이는 글로벌 트렌젝션으로 수행한다.
MQ를 사용하면 이벤트 발행과 핸들러가 다른 JVM에서 이루어진다.
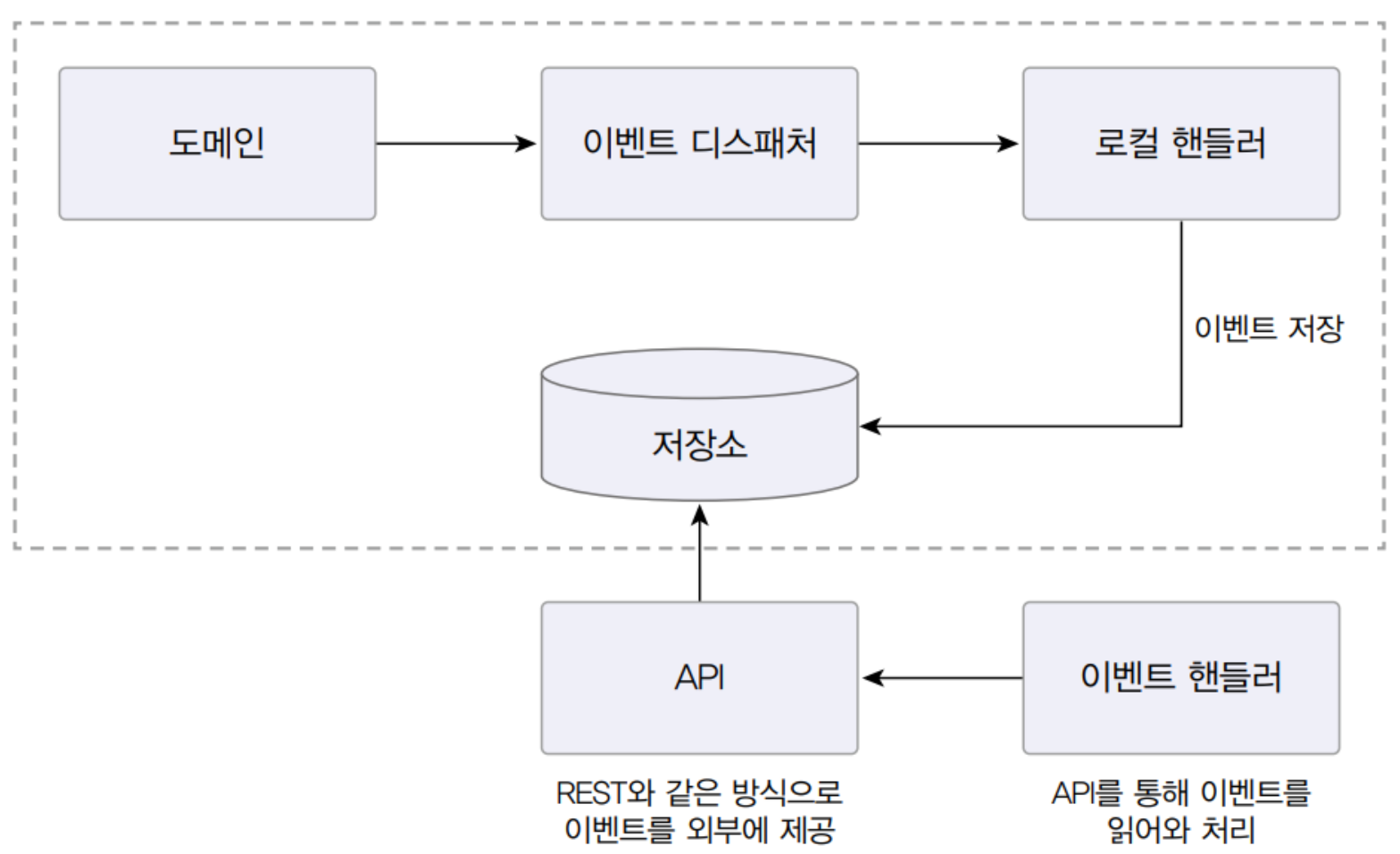
이벤트 저장소를 이용한 비동기 처리
이 방식은 이벤트를 일단 DB에 저장한 뒤 별도 프로그램을 이용해서 이벤트 핸들러에 전달하는 것 이때 저장소에서 이벤트를 읽도록 하는 주체가 누구인지에 따라 포워드 방식과 API방식으로 나뉜다.
CQRS
앞서 언급한 다른 애그리거트를 식별자로 참조하는 방식은 성능 이슈가 있다. 또한 도메인 상태 변경 에 적합한 ORM 기능으로 조회를 구현하는 것은 구현을 복잡하게 만드는 원인이 된다. 이를 해결하기 위해 CQRS를 도입한다.
필요에 따라서는 명령과 조회를 다른 저장소를 사용할 수 있다. 이를 위해 일반적으로 명령은 OLTP 저장소를, 조회는 OLAP저장소를 사용하곤 한다. 그리고 두 저장소를 동기화 하기 위해 앞서 배운 이벤트를 활용한다.