데이터 파이프라인 핵심 가이드[03_일반적인 데이터 파이프라인 패턴]
http://www.yes24.com/product/goods/106729751
데이터 파이프라인 핵심 가이드 - YES24
데이터 파이프라인의 모든 단계를 기초부터 탄탄하게 설명한다!데이터 파이프라인은 데이터 분석의 성공을 위한 기이다. 수많은 다양한 소스에서 데이터를 이동하고 컨텍스트를 제공하기 위해
www.yes24.com
책 목차:
01_데이터 파이프라인 소개: https://inhyeok-blog.tistory.com/m/28
02_최신 데이터 인프라: https://inhyeok-blog.tistory.com/29
03_일반적인 데이터 파이프라인 패턴: https://inhyeok-blog.tistory.com/30
04_데이터 수집: 데이터 추출:
05_데이터 수집: 데이터 로드:
06_데이터 변환하기:
07_파이프라인 오케스트레이션:
08_파이프라인의 데이터 검증:
09_파이프라인 유지 모범 사례:
10_파이프라인 성능 측정 및 모니터링:
데이터 파이프라인 설계는 다양한 제약사항(준 실시간성, 최종 설과가 ML모델 or 대시보드 등)이 존재한다. 따라서 숙련된 엔지니어도 데이터 파이프라인 설계는 어려운 일이다. 하지만 이를 해결하기 위한 몇가지의 패턴을 통해서 도움을 받을 수 있다.
1. ETL과 ELT
ETL과 더 현대적인 ELT, 두 패턴 모두 데이터 웨어하우스에 데이터를 공급하고 분석가나 보고 도구가 이를 유용하게 쓸수 있게 하는 데이터 처리에 대한 접근 방식이다.
Extract(추출): 로드 및 변환을 준비하기 위해 다양한 소스에서 데이터를 수집하는 단계
Load(로드): 원본 데이터(ETL의 경우) 또는 변환된 데이터(ELT의 경우)를 최종 대상(데이터 웨어하우스, 데이터 레이크 등)으로 가져오는 단계
Transform(변환): 분석가, 시각화 도구 등에 유용하게 쓸 수 있도록 소스 시스템의 원본 데이터를 결합하고 형식을 지정하는 단계
2. ETL을 넘어선 ELT의 등장
ETL은 수십년동안 데이터 파이프라인의 표준이었다. 이 표준은 여전히 사용되고 있지만(심지어 어떤 상황에서는 ELT보다 유리하다[https://dining-developer.tistory.com/50]) 최근에는 ELT라는 추가 선택지가 등장했다. 이는 대용량 스토리지와 높은 컴퓨팅 파워를 가진 클라우드 서비스의 등장고, 열-기반 DBW(SnowFlake/RedShift/Bigquery)의 등장이 배경이 된다.
예전에는 방대한 양의 원보데이터를 로드하고 이를 사용 가능한 데이터로 변환하는 데 필요한 스토리지나 컴퓨팅 자원이 모두 모여있는 데이터 웨어하우스에 액세스할 수 없었다. 하지만 클라우드 컴퓨팅을 통해 확장에 용이한 환경을 구성할 수 있게 된 것이다.
또한 열-기반 DBW는 OLAP(온라인 분석 처리)를 더 효과적으로 처리할 수 있도록 했다. DB의 I/O효율성, 데이터 압축, 데이터 처리를 위한 여러 병렬 노드에 데이터 및 쿼리를 분산하는 기능을 통해 데이터 변환(Transform)은 열-기반 DBW에서 담당하고, 파이프라인은 데이터 로드(Load)에 집중할 수 있게 된 것이다.
column store database의 신흥 강자 ClickHouse도 시간나면 살펴보자
3. EtLT 하위패턴
ELT가 지배적인 패턴이 되었지만, 그럼에도 로드하기 전에 약간의 변환은 필요하다. 이때의 변환은 비즈니스 논리 또는 데이터 모델링을 위한 변환이 아니라 민감한 데이터를 마스킹 하는 것과 같이 법적 또는 보안상의 이유로 파이프라인 초기에 필요한 것이다.
- 테이블에서 레코드 중복 제거
- URL 파라미터를 개별 구성요소로 구문 분석
- 민감함 데이터 마스킹 또는 난독화
4. 데이터 분석을 위한 ELT
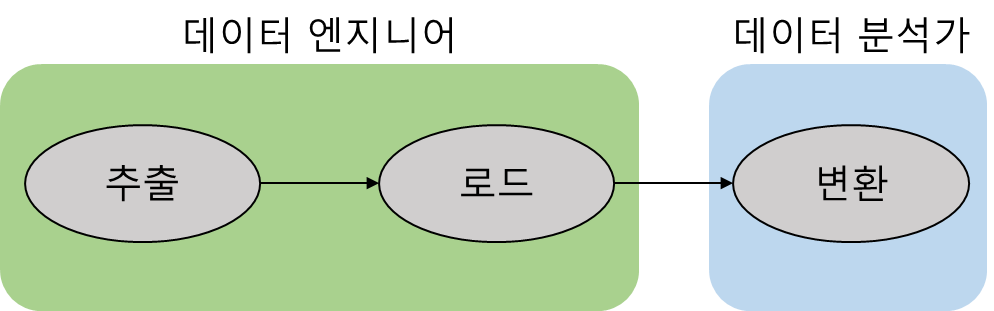
데이터 엔지니어는 데이터 파이프라인 전체를 구성하는 일을 하고, 데이터 분석가는 수집된 데이터를 기반으로 유의미한 정보를 얻어내는 일을 한다. 이때, 유의미한 정보를 얻어내는 일은 데이터 파이프라인에서 변환(Transform)에 해당하는 일인데, 기존의 ETL에서는 데이터 분석가가 데이터 파이프라인 전반에 걸쳐서 작업을 수행해야했다. 하지만 ELT의 경우에는 추출(Extract)와 로드(Load)를 데이터엔지니어가 담당하고, 데이터 분석가서 변환(Transform)을 담당하므로서, 팀 구성원들이 더 낮은 상호 의존성을 휙득하여 ELT 자체의 강점에 집중할 수 있다. 또한 ELT패턴은 데이터 엔지니어가 분석가가 데이터로 수행할 작업을 정확히 예측해야 하는 필요성을 줄여준다. ELT의 경우 변환 단계를 나중으로 넘김으로써 분석가에게 더 많은 옵션과 유연성을 제공할 수 있는 것이다.
5. 데이터 제품 및 머신러닝을 위한 ELT
데이터는 분석, 보고 및 예측 모델 이상의 용도로 사용된다. 데이터 제품을 강력하게 만드는 데도 사용되는데, 데이터 제품의 몇 가지 일반적인 예는 다음과 같다.
비디오 스트리밍 홈 화면을 구동하는 콘텐츠 추천 엔진
전자상거래 웹사이트의 개인화된 검색 엔진
사용자가 생성한 레스토랑 리뷰에 대한 감성분석을 수행하는 애플리케이션
이런한 각 데이터 제품은 ML모델에 의해 구동될 가능성이 높다. 이러한 데이터는 다양한 소스 시스템에서 가져올 수 있으며 모델에서 사용할 수 있도록 일정 수준의 변환을 거칠 수 있다.
- 머신러닝 파이프라인의 단계
데이터 수집 - 데이터 전처리 - 모델 학습 - 모델 배포
- 파이프라인에 피드백 통합
좋은 ML파이프라인은 모델 개선을 위한 피드백 수집도 포함된다. (최근에는 A/B테스팅도 중요하다.) 이를 위해서 사용자들의 행위를 수집해서 데이터 웨어하우스로 다시 수집하고, 학습 데이터 또는 미래 모델이나 실험에 쓰기 위해 모델의 향후 버전에 통합 할 수 있다.